 E-BLEARN
E-BLEARN
Page
Chapitre 1 : Introduction Data & Python
Conditions d’achèvement
Disponible à partir du 02/04/2025 au 05/05/2025
![]()
Introduction Data & Python
Overview
Analyse des données
Introduction
Data, Qu'est ce que c'est?
Analyse de données, qu'est ce que c'est?
Impact d'analyse de données sur les entreprises
Défis et opportunités
Résolution des problèmes commerciaux à l'aide de l'analyse de données Comment les entreprises résolvent-elles les problèmes?
Où se situe l'analyse des données ?
Comment l'analyse affecte-t-elle les générateurs de valeur lors de la planification? et étapes de mesure pour résoudre un problème commercial?
Prendre des décisions qui définissent l'entreprise à l'aide de l'analyse de données
Le cadre de données et d'analyse
Les 4 aspects du cadre de données et d'analyse
Cadre de données et d'analyse: outils et techniques
Data Management avec un Data Lab Problèmes de gestion des données Qu’est-ce qu’un Dta Lab ?
Les enjeux d’un Data Lab
Comment mettre en place un Data Lab ?
Différents typologies en fonction du pourcentage des rôles
IT-centrique
Structure intégrée
Département spécialisé en Data science
Compétence requise par rôle:
Comment outiller le Data Lab ?
Centraliser les données disponibles mettre en place un Data Lake
L'exploitation d'un Data Lake par le Data Lab implique l'utilisation d'un certain nombre de technologies :
Méthode CRISP : mode d’emploi
L’Expérimentation des données Paradigme
Comment choisir le cas d'usage
Le déroulement des POCs
Techniques et outils d'analyse des données
Introduction aux techniques d'analyse de données
Explorer les outils d'analyse de données
SQL
Python
Une brève introduction à SQL
Qu'est-ce que c'est MySQL?
Introduction à la base de données
SQL - le langage de la base de données relationnelle
MySQL
Installez MySQL
Télécharger MySQL Installer
Installer MySQL via MySQL Installer
Se connecter au serveur MySQL
Se connecter à MySQL à l'aide du client de ligne de commande mysql
Se connecter à MySQL à l'aide de MySQL Workbench
Exemple de base de données MySQL
Télécharger la base de données exemple MySQL
Comment charger l'exemple de base de données dans le serveur MySQL
Mongo overview
Guide d'installation du Mongo DB:
Vérification
Utilisation
Insert
Read
Supression d'une collection et d'une database
Introduction à Python
Langages
Langage humain
Langage machine
Langages de programmation
Bref histoire du Python
Pourquoi Python pour ce programme Data?
Un langage de programmation interprété
Installer Python avec Anaconda
Téléchargez et installez Anaconda
Ajouter Anaconda au chemin (facultatif)
Premier pas avec Jupyter Notebook - Python Introduction à Jupyter Notebook
Notions de base sur Jupyter Notebook
Jupyter Notebook Dashboard
Présentation de UI(User interface) du notebook
Mode édition
Mode commande
Navigation avec la souris
Navigation avec le clavier
Premiers tests
Texte "Hello world"
Calculs natifs
Saisir un nombre
Opérations
Addition, soustraction, multiplication, division
Division entière et modulo
Premiers pas vers la programmation
Variables
Définition d'une variable
Opérations sur une variable
Types de données
Déclaration du type de données
Introduction aux différents types de données
Python - Nombres entiers
Python - Nombres flottants
Python - Chaînes de caractères
La fonction len () renvoie la longueur d'une chaîne:
La méthode strip () supprime tout espace du début ou de la fin:
La méthode lower () renvoie la chaîne en minuscules:
La méthode upper () renvoie la chaîne en majuscules:
La méthode replace () remplace une chaîne par une autre chaîne:
La méthode split () divise la chaîne en sous-chaînes si elle trouve des instances du séparateur:
Pour vérifier si une certaine phrase ou un certain caractère est présent dans une chaîne, nous pouvons utiliser les mots clés in ou not in .
f-Strings: une façon nouvelle et améliorée de formater les chaînes en Python
Python - Listes
Pour déterminer le nombre d'éléments d'une liste, utilisez la fonction len () :
Ajouter de nouveaux éléments à la fin de la liste, en utilisant la méthode append () :
Pour ajouter un élément à l'index spécifié, utilisez la méthode insert () :
La méthode remove () supprime l'élément spécifié:
La méthode pop () supprime l'index spécifié, (ou le dernier élément si l'index n'est pas spécifié):
Le mot clé del supprime l'index spécifié:
Faites une copie d'une liste avec la méthode copy () :
Rejoignez deux listes
Structures conditionnelles Déclaration if
Déclaration else Déclaration elif
Opérateurs de comparaison
Mots-clés and , or et not
Boucles
Python - Boucle for - for Loop
Python - Fonction range ()
Python - Boucle while - while Loop
Exercice 4.4.3 - 1 : Comment pouvons nous réécrire le programme de la section 4.4.2 avec la boucle while ?
Exercice 4.4.3 - 2 : Quelle est la somme de tous les nombres entiers entre 1 et 100(Avec les deux bords inclus)? - Utilisons la boucle while
Avancer dans la programmation
Fonctions
Mot-clé def
Table de multiplication par 9
Exercice 5.1.2 - 1 Instruction Return
Premier programme
Fonction input()
Un simple programme pour déterminer si une année est bissextile
Un peu de simplification
Gérez les exceptions
Try - Except
Déclaration finally
Déclaration pass
Les assertions - assert
Conception de classe
Premier aperçu de classe
Syntaxe de définition de classe
Objets de classe
Un exemple simpliste - Matrices help() __repr__()
L'attribut spécial __dict__
Les propriétés
Implémentation 01 - Simple
Implémentation 02 - Interface getter/setter
Implémentation 03 - Implémentation pythonique
Implémentation de Temperature
Time - Un exemple de classes de la bibliothèque standard
Le module time
Le module Datetime()
Définition des classes par leur constructeur
Date
Time
Datetime
Cas pratiques:
Afficher la datetime actuelle:
Renvoyez l'année ou d'autres composantes: Création d'un objet de date affichage d'une datetime
lire une chaine de caractères de datetime
Les Méthodes spéciales
Édition de l'objet
__init__
__del__
Accès aux attributs de notre objet
__getattr__
__setattr__
La méthode spéciale derrière le mot-clé in
D'autres opérateurs
__iadd__
Importer votre propre module
Etape 01 - Nouveau Notebook
Etape 02 - Créer votre classe de test et télécharger le fichier en .py
Importer votre propre module
Importer des objets individuels
1.Overview
Le marché moderne des entreprises est un environnement axé sur les données. Le rôle des données est de permettre aux chefs d'entreprise de prendre des décisions basées sur des faits, des tendances et des chiffres statistiques. Mais avec autant d'informations disponibles, les chefs d'entreprise doivent être capables de passer au crible le bruit et d'obtenir les bonnes informations, afin de pouvoir prendre les meilleures décisions en matière de stratégie et de croissance.
Les données sont au cœur de presque toutes les décisions commerciales prises. Les directeurs des ressources humaines collectent des données à partir des ressources en ligne pour déterminer les meilleures personnes à recruter et confirmer les détails à leur sujet. Les services marketing s'appuient sur les données de segmentation du marché pour trouver des consommateurs prêts à acheter, accélérant le processus de clôture des ventes chaque fois que possible. Les dirigeants d'entreprise doivent examiner les tendances plus importantes du marché, telles que les changements de prix des ressources, d'expédition ou de fabrication.
En utilisant efficacement les données, une entreprise est en mesure de rationaliser le processus de fabrication d'un produit et de le remettre entre les mains du client.
 2.Analyse des données
2.Analyse des données
2.1 Introduction
Le changement technologique rapide signifie que la façon dont nous traitons les données est
fondamentalement différente aujourd'hui qu'elle ne l'était il y a quelques années à peine. Dans cette session, nous allons discuter de ce que sont les données et les analyses et pourquoi elles sont importantes. L'impact que cela a sur les entreprises et comment il peut aider les organisations à prendre des décisions meilleures et plus rapides.
2.1.1 Data, Qu'est ce que c'est?
Webster définit les données comme un ensemble de faits, d'observations ou d'autres informations liées à une question ou un problème particulier. Les données peuvent être structurées ou non structurées.
Les données structurées sont des informations avec un haut degré d'organisation qui pourraient être incluses dans des bases de données ou des feuilles de calcul et sont facilement consultables par de simples algorithmes de moteur de recherche. Comprenons les données structurées avec un exemple des cotations boursières:

Les données non structurées sont l'opposé et sont généralement lourdes en texte, bien qu'elles puissent également contenir des vidéos, des données ou des chiffres et des faits. Pensez à une zone de texte de champ ouvert qui vous permet de fournir des commentaires supplémentaires sur une enquête.
Voici un exemple :
 Un fichier d'image peut être considéré comme donnée non structurée. Les données sous forme
Un fichier d'image peut être considéré comme donnée non structurée. Les données sous forme
vidéo peuvent également considérées comment les données non structurées
Les données peuvent également provenir de diverses sources internes et externes pour les organisations. La conversation devient vraiment intéressante lorsque nous examinons la grande variété de données dont nous disposons aujourd'hui et les puissantes analyses qui peuvent être appliquées à ces données.
2.1.2 Analyse de données, qu'est ce que c'est?
L'analyse des données est la science d'examiner des données brutes afin de tirer des conclusions sur les informations. C'est un domaine passionnant qui a un impact considérable sur la façon dont les organisations de nombreuses industries prennent des décisions.
La disponibilité d'énormes volumes de données structurés et non structurés, combinés à des capacités informatiques avancées. Le stockage à faible coût et la puissante technologie de visualisation permettent aux organisations d'obtenir des informations. Ce qui était technologiquement impossibles ou économiquement irréalisables. Cela permet également à de nouvelles entités de démarrer et de se développer rapidement. Ce qui peut apporter de grands avantages au marché et à la société, mais peut également être très perturbateur. D'où viennent donc ces données? Des études de marché et des médias sociaux au réseau d'objets physiques, nous appelons l'Internet des objets(Internet of things, ou IoT). Le monde dans lequel nous vivons aujourd'hui crée un flux de données constant et toujours croissant. Pour la plupart des organisations, les données auxquelles elles peuvent accéder augmentent à un taux de 40% chaque année, ce qui crée des défis importants dans la façon dont les données sont capturées et sécurisées, organisées, analysées et rapportées.
2.1.3 Impact d'analyse de données sur les entreprises
Premièrement, les données permettent de nouveaux produits et services, créant des marchés qui n'existaient pas auparavant et apportant de nouvelles capacités aux marchés existants.
 Les appareils portables, tels que votre Fitbit ou votre montre Apple, sont quelques exemples de nouveaux produits.
Les appareils portables, tels que votre Fitbit ou votre montre Apple, sont quelques exemples de nouveaux produits.
Deuxièmement, il perturbe les marchés existants avec des nouveaux arrivants qui détruisent les entreprises traditionnellement sécurisées.
-
 Uber - Taxi partagé.
Uber - Taxi partagé.
Troisièmement, les données et les analyses améliorent l'efficacité.
-
 Par exemple, les détaillants ont la possibilité d'automatiser et d'optimiser leur chaîne
Par exemple, les détaillants ont la possibilité d'automatiser et d'optimiser leur chaîne
d'approvisionnement. Adapter les offres pour les clients rendant des services tels que la livraison le jour même d'Amazon dans les grandes villes américaines logistiquement possible.
En bref, les données permettent aux organisations d'identifier les opportunités de croissance, de stimuler l'innovation, de fonctionner plus efficacement et de gérer les risques de nouvelles manières.
2.1.4 Défis et opportunités
Donc, si les données peuvent faire tout cela, les organisations doivent simplement les utiliser pour rester compétitives, mais comment? Les organisations ont toujours utilisé les données sous une forme ou une autre pour éclairer leurs décisions.
Mais le volume, la variété et la vitesse des données disponibles aujourd'hui présentent d'énormes défis. Les approches traditionnelles de l'analyse des données(identifier un problème ou une opportunité commerciale, collecter des données et utilisent des feuilles de calcul ou des logiciels pour comprendre ) ne s'appliquent plus. Aujourd'hui, le volume d'informations est tout simplement trop élevé et le délai trop court. Faire face à ces défis peut conduire à une immense récompense. Les organisations intelligentes profitent de l'analyse des données pour obtenir une image plus claire de leur entreprise. Ils utilisent de nouvelles technologies telles que la visualisation des données. La présentation des données dans un format graphique pour aider les décideurs à voir les analyses présentées visuellement et à identifier plus facilement de nouveaux modèles. Ce type de perspicacité est puissant et peut fondamentalement changer la vitesse et la façon de la prise de décision.
2.1.5 Résolution des problèmes commerciaux à l'aide de l'analyse de données
Dans cette section , nous verrons comment les entreprises utilisent les données et les analyses pour améliorer la prise de décision en partageant avec vous quelques études de cas.
Les organisations tentent constamment de s'améliorer et de se transformer, que ce soit pour relever des défis stratégiques périodiques ou des améliorations opérationnelles quotidiennes. Il existe un processus de prise de décision commerciale. Nous savons que les dirigeants prêtent attention à ce que les données et l'analyse leur disent, c'est la partie scientifique de l'équation. Mais nous savons aussi qu'ils dépendent fortement de l'art de l'intuition, où sa propre expérience, sa vision du marché et ce qu'ils entendent des conseillers.

Plus de 50 ans plus tard, de nombreux chefs d'entreprise continuent de s'appuyer fortement sur l'intuition pour prendre des décisions vraiment importantes.
Dans les conversations avec les chefs d'entreprise, nous entendons souvent dire que les dirigeants ont à tout moment accès à de grandes quantités de données. Mais nous entendons également qu'un facteur majeur dans leur prise de décision vient de leur propre intuition. La question est, comment mieux combiner l'art et la science de la prise de décision?
Une utilisation plus efficace des données est de combiner la capacité d'extraire des informations, offrir aux organisations des opportunités de générer plus de valeur. L'intégration de l'analyse dans la culture de prise de décision d'une organisation peut aider les organisations à croître et à innover, à fonctionner plus efficacement et à mieux gérer les risques.


En résumé, les organisations tentent constamment de s'améliorer, qu'elles s'attaquent à de nouveaux défis et opportunités ou tentent d'apporter des améliorations opérationnelles. Lorsque nous superposons des données et des analyses sur ce processus, le résultat est une prise de décision meilleure et plus rapide. Dans la section suivante, nous examinerons en profondeur le processus de données et d'analyse utilisé pour aider à prendre de grandes décisions.
2.1.5.1 Comment les entreprises résolvent-elles les problèmes?
Prise de décision basée sur les données:
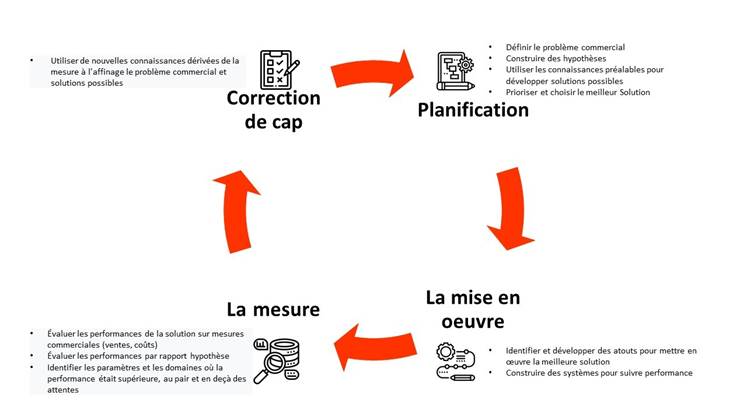
2.1.5.2 Où se situe l'analyse des données ?
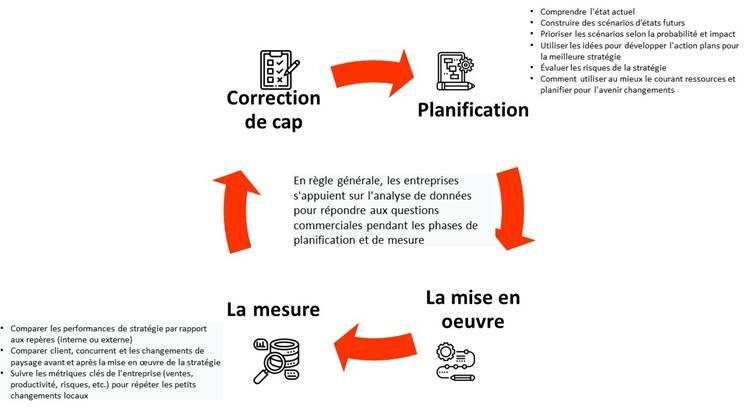
2.1.5.3 Comment l'analyse affecte-t-elle les générateurs de valeur lors de la planification? et étapes de mesure pour résoudre un problème commercial?
|
Générateur de Valeur |
Phase de planification |
Phase de mesure |
|
Revenu |
• Trouver un nouveau segment demarché pour les produits à gagner nouveaux clients • Identifier les besoins des clientspour réaliser plus de ventes par client • Élaborer des stratégies de prix pour acquérir part de marché • Évaluer l'impact des actionsattendues des concurrents |
• Évaluer le succès du comportementd'achat des clients changé après la stratégie • Évaluer la position concurrentielle duproduit dans le marché • Suivre les revenus, les changements departs de marché |
|
Coût |
• Identifier les domainesd’amélioration de la productivité • Construire un déploiement optimal des ressources pour mettre en œuvre la stratégie • Analyse de rentabilité ROI de lastratégie planifiée |
• Calculer le retour sur investissement réalisé en mettre en œuvre des changements de productivité • Suivre la mise en œuvre des changements au sein de l'organisation |
|
Conformité |
• Évaluer les risques et les coûts de conformité pour la stratégie planifiée |
• Vérifier en permanence les nouveaux problèmes de conformité et les changements du marché |
2.1.6 Prendre des décisions qui définissent l'entreprise à l'aide de l'analyse de données
Dans l'environnement actuel, les organisations fortement axées sur les données prennent des décisions meilleures et plus rapides. Nous pensons que les données et les analyses peuvent faire une énorme différence quand il s'agit des décisions les plus importantes concernant l'orientation stratégique d'une organisation. Voyons maintenant comment les données aident les organisations à prendre des décisions.
Les entreprises prennent des milliers de décisions par jour. La plupart sont de routine, beaucoup sont étayés par des données. Un nombre croissant peut être automatisé, mais que se passe-t-il lorsqu'il s'agit de décisions qui vont au-delà des opérations quotidiennes? Des décisions qui changeront le cours d'une entreprise, ou même d'une industrie, et façonneront le monde dans lequel nous vivons. C'est ce que nous appelons de grandes décisions.
Pour penser aussi largement que la technologie le permet, nous devons réunir nos atouts les plus puissants, l'art de l'instinct et l'expérience de la science des données et de l'analyse.
Ainsi, les décisions telles que la croissance ou la réduction de l'entreprise ou la collaboration avec des concurrents sont perçues plus clairement.
Nous aurons plus d'occasions d'identifier, de modéliser et de cartographier plusieurs futurs, en réduisant les risques d'innovation et en accélérant le processus décisionnel.
Les dirigeants des organisations fortement axées sur les données sont trois fois plus susceptibles de signaler des améliorations significatives de leurs décisions.
Dans la prochaine section, nous présenterons le cadre de données et d'analyse. Et comment le cadre de données et d'analyse peut être appliqué de manière cohérente pour résoudre les problèmes.
2.2 Le cadre de données et d'analyse
Dans cette section, nous allons examiner le cadre de données et d'analyse. Nous allons parler des compliments du cadre et expliquer pourquoi il est important de suivre un cadre lors de la résolution d'un problème commercial.
![]() “
“
Exemple:
Une compagnie d'assurance mondiale est venue à nous avec le désir d'incorporer des données et des analyses avancées dans son organisation. Il s'agit d'un certain nombre d'objectifs commerciaux qu'ils souhaitaient atteindre, notamment l'amélioration de la rétention et des ventes croisées dans un pays et l'augmentation des acquisitions dans un autre pays. Ils voulaient construire une organisation analytique, tout en s'assurant de résoudre un problème commercial. Nous avons examiné notre cadre de données et d'analyse pour déterminer d'abord les résultats dans chaque pays. Par exemple, comme nous l'avons dit, une plus grande détention de produits croisés dans un pays. Ensuite, nous avons énuméré toutes les actions ou décisions qu'ils peuvent prendre pour obtenir ce résultat. Par exemple, qui cibler, quand, pourquoi et par quel canal.
Cela nous a amenés à étudier comment ils prenaient ces décisions aujourd'hui et comment ils pouvaient être améliorés avec de meilleures perspectives. Par exemple, des informations sur le meilleur produit suivant, les préférences de canal. Cela nous a conduits aux techniques nécessaires pour générer ces informations et aux données nécessaires pour générer ces informations. Alors pourquoi avons-nous besoin d'un cadre de données et d'analyse? La réponse courte est un cadre qui vous permet de parcourir l'analyse des données de manière organisée. Il vous fournit un processus à suivre lorsque vous travaillez avec vos équipes et vos clients pour résoudre les problèmes. Le cadre nous permet de nous concentrer d'abord sur les résultats commerciaux et sur les actions et les décisions qui assurent les résultats. Il concentre notre attention sur ce qui génère de la valeur pour les organisations avant d'examiner toutes les données que nous avons ou celles que nous n'avons pas qui doivent être obtenues. En résumé, le cadre nous permet de structurer une discrétion avec l'organisation et de suivre un chemin qui mène à des informations exploitables et à des résultats commerciaux.
2.2.1 Les 4 aspects du cadre de données et d'analyse
Notre cadre comporte quatre aspects. Découvertes, Perspectives, Décisions et actions, Résultats
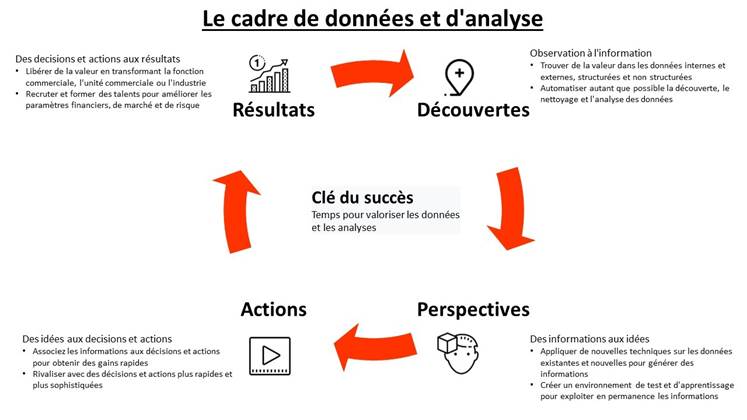
Pendant la phase de découverte, vous devez définir le problème, développer une hypothèse et collecter et explorer des données. Pendant les analyses, vous effectuez l'analyse des données. Viennent ensuite les actions où vous liez des informations à des recommandations exploitables et à un plan d'exécution. Enfin, vous passez en revue les résultats qui ont transformé l'entreprise ou l'unité commerciale ou l'industrie. Nous partons des résultats commerciaux pour définir le problème que nous essayons de résoudre. Nous examinons souvent les questions auxquelles il faut répondre ou les problèmes clés qui doivent être résolus. Les métriques qui doivent être prises en compte. Cela nous permet non seulement de définir le problème, mais aussi de formuler notre hypothèse sur la façon dont nous allons influer sur les résultats. Une fois que nous avons déterminé les résultats à atteindre, nous examinons les décisions que les dirigeants doivent prendre ou les actions que les employés doivent prendre. Cela nous permet d'identifier les variables dépendantes critiques, les décisions ou les actions, ou la sortie requise pour prendre les bonnes décisions et actions. En fonction de la complexité du problème et du temps disponible, nous examinons différentes techniques qui peuvent être utilisées pour générer ces informations. Cela commence généralement par comprendre d'abord ce qui s'est passé jusqu'à présent, ce que l'organisation a fait et comment elle peut le faire à l'avenir, afin que nous puissions influencer les décisions et les actions clés. Une fois que nous avons les techniques qui généreront les informations, nous pouvons rechercher les bonnes données disponibles. Les données peuvent être internes ou externes à l'organisation. Il peut également être structuré ou non structuré. La plupart ont offert les données disponibles, le temps disponible pour les obtenir, mais influencent les techniques que nous pourrions potentiellement utiliser pour générer des informations. Eh bien, c'est un processus itératif. Il est toujours préférable de partir des résultats et de l'hypothèse plutôt que des données disponibles pour générer la meilleure valeur à partir des données et des analyses.
![]() “
“
Récapitulons donc le cadre d'analyse des données.
![]() Pendant la phase de découverte, vous définissez le problème, développez une hypothèse et collectez et explorez les données. Pendant les analyses, vous effectuez l'analyse des données. Actions est l'endroit où vous liez des informations à des recommandations exploitables, puis au plan d'exécution.
Pendant la phase de découverte, vous définissez le problème, développez une hypothèse et collectez et explorez les données. Pendant les analyses, vous effectuez l'analyse des données. Actions est l'endroit où vous liez des informations à des recommandations exploitables, puis au plan d'exécution.
Enfin, vous passez en revue les résultats des objectifs et des solutions à long terme.
Ce cadre nous permet de parcourir l'analyse des données de manière organisée et de nous fournir le processus à suivre lorsque nous travaillons avec les organisations pour résoudre un problème. Dans la section suivante, nous allons parler des types d'analyses que vous pouvez effectuer et vous montrer les outils que vous pouvez utiliser dans le cadre d'analyse de données.
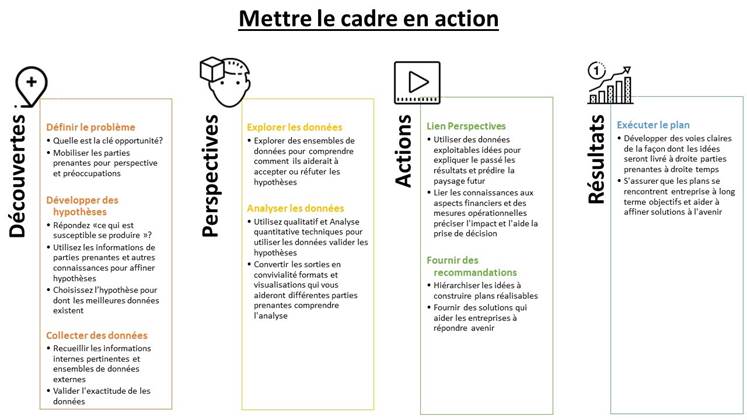
2.2.2 Cadre de données et d'analyse: outils et techniques
Maintenant que nous avons présenté les données et le cadre analytique, nous devons répondre à la question :"quelles techniques analytiques puis-je utiliser et quels outils peuvent m'aider ". Dans cette sous-section, nous allons parler de cinq types d'analyses de données et des outils utilisés pour aider à construire notre analyse. Nous classons les types d'analyses que l'on peut faire en cinq types.
![]() Analyse descriptive
Analyse descriptive
Analyse diagnostique
Analyse prédictive
Analyse prescriptive
Analyse adaptative et autonome
Ce sont les grandes catégories qui vous aideront à fournir le cadre de données et d'analyse dont nous avons discuté dans la 2.2.1 Le cadre est abstrait, mais ces types d'analyses vous aideront à le rendre opérationnel.
Comme nous l'avons vu précédemment, l'une des utilisations courantes de l'analytique en marketing est la vente croisée de plusieurs produits aux clients. Lorsque nous avons examiné les résultats de l'augmentation du nombre de produits différents, nous avons commencé par l'analyse descriptive. Nous avons examiné leurs données pour profiler leurs clients. Ces profils comprenaient les données sociodémographiques du client, leurs comportements en ligne et hors ligne, leurs attitudes, les étapes de la vie à laquelle ils ont acheté ces produits, et bientôt.
L'analyse descriptive vous aide à comprendre l'état actuel des choses dans une organisation. Il vous permet de regarder ce qui se passe aujourd'hui et c'est ce qui s'est passé dans le passé. Ce type d'analyse fournit généralement des informations résumées pour comprendre les modèles de vente ou le comportement du client, la rentabilité du client, les actions passées des concurrents, etc. Les techniques spécifiques peuvent inclure de simples diagrammes en boîte, des histogrammes avec des moyennes, des minimums et des maximums. Tracer les données en quartiles ou déciles sur un certain nombre de variables différentes. Ou calculer des mesures statistiques comme la moyenne, le mode, l'écart-type, etc. L'analyse descriptive est très puissante pour comprendre l'état actuel des choses et pour développer l'hypothèse afin d'anticiper où se situent les problèmes et les opportunités d'affaires. Cela nous aide à répondre à la question, que s'est-il passé? Par exemple, à partir de l'analyse descriptive, il était clair qu'une grande proportion des clients de la compagnie d'assurance dont nous avons parlé dans la section précédente, n'avaient qu'un seul produit, et un très petit nombre de clients avaient quatre produits ou plus.
Après avoir eu une bonne description de la détention de produits croisés des différents clients, nous avons commencé à chercher pourquoi la détention de produits croisés était si faible. Il s'est avéré que la compagnie d'assurance avait plusieurs canaux pour vendre ses produits: des agents captifs, des agents indépendants et du personnel de télémarketing. Chacun de ces canaux a bien vendu un type de produit spécifique, ce qui s'est traduit par un nombre égal de clients d'un produit sur les trois canaux. Compte tenu de l'expertise de ces chaînes, il y a eu très peu de ventes croisées. La détention de produits multiples était davantage le résultat de clients exigeant des produits supplémentaires, par opposition à tout processus de vente croisée délibéré.
L'analyse diagnostique vous aide à comprendre pourquoi cela s'est produit. Il fournit les raisons de ce qui s'est produit dans le passé. Ce type d'analyse tente généralement d'approfondir une raison ou des hypothèses spécifiques basées sur l'analyse descriptive. Alors que l'analyse descriptive jette un large filet pour comprendre l'étendue des données, l'analyse diagnostique va en profondeur, explorant les causes des problèmes. Par exemple, nous pourrions envisager de créer une analyse d'arbre de décision des portefeuilles de produits croisés pour révéler les types de clients qui ont acheté ces produits, les canaux qu'ils utilisent, les produits qu'ils ont achetés et quand ils les ont achetés. Une fois que nous avons su quels étaient les principaux problèmes dans un portefeuille de produits à bas prix, nous avons commencé à formuler des hypothèses sur ce que nous pouvons faire pour augmenter les ventes croisées de produits. Nous avons construit un modèle prédictif pour classer les clients selon leur propension à acheter un deuxième, un troisième ou un quatrième produit spécifique. Ce modèle prédictif a été construit sur la base de la compréhension que nous avons acquise des deux étapes précédentes de l'analyse descriptive et diagnostique. Ensuite, nous avons l'analyse prédictive. Contrairement à l'analyse descriptive ou diagnostique, l'analyse prédictive est plus prospective. L'analyse prédictive vous permet d'imaginer ce qui pourrait arriver à l'avenir. Ce type d'analyse peut aider le client à répondre à des questions telles que: que feront probablement mes clients à l'avenir? Que sont susceptibles de faire mes concurrents? À quoi ressemblera le marché? Comment l'avenir affectera-t-il mon produit ou service? L'analyse prédictive prédit généralement ce qui pourrait se produire sur la base des preuves que nous avons vues.
Dans notre étude de cas sur l'assurance Exemple 2.2 , une fois que nous avons construit notre modèle de propension, nous avons pu identifier certaines des cibles à fort potentiel de vente croisée et quel produit elles devraient être vendues de façon croisée. Compte tenu des différentes propensions à acheter, nous avons calculé la meilleure offre suivante pour chaque client et comment le message de vente croisée devrait être personnalisé pour chaque client et canal de distribution. L'analyse prescriptive va au-delà de la formulation de recommandations pour exécuter réellement les actions ou prendre les décisions qui conviennent à une situation particulière. Pour ce faire, il examine ce qui s'est passé dans le passé, l'état actuel et toutes les possibilités futures. L'analyse prescriptive fournit des réponses à la question, quelles mesures ou interventions doivent être prises pour atteindre les résultats souhaités? Souvent, l'intervention peut être une solution optimale compte tenu des circonstances. Ou la meilleure action possible étant donné l'incertitude dans l'environnement et les informations limitées disponibles. Elle implique fréquemment l'analyse de scénarios et / ou la recherche de solutions optimales. L'analyse prescriptive est puissante pour comprendre les bonnes actions nécessaires aujourd'hui pour répondre aux possibilités futures et mettre une organisation la meilleure position possible pour tirer parti des conditions futures. Bien que nous ayons créé une solution unique pour que le client augmente la détention de produits croisés de ses clients, ce dont ils avaient vraiment besoin était un système adaptatif et continu qui apprend des interventions comportementales et des actions prises par les clients pour modifier automatiquement les
recommandations et essayer de nouvelles mesures. Une telle plateforme de perspicacité permanente où le système construit un modèle du monde réel, prend des mesures, apprend de l'environnement et s'adapte en permanence est la solution adaptative et autonome ultime.
L'analyse adaptative et autonome en est encore à ses balbutiements, la plupart des systèmes sont aujourd'hui prédictifs ou normatifs. Très peu d'entre eux sont complètement adaptatifs ou autonomes. Cependant, il existe un certain nombre d'entreprises qui construisent des solutions analytiques plus adaptatives ou autonomes où nous éliminons l'humain dans la boucle. La conduite autonome est un excellent exemple de solution analytique adaptative ou autonome. L'analyse adaptative et autonome fournit des réponses à la question de savoir comment le système s'adapte aux changements? Comment exécuter des solutions analytiques en mode continu? Apprendre et corriger en permanence son comportement pour optimiser ses performances.
Nous ne voulons peut-être pas construire des systèmes adaptatifs et autonomes dans tous les cas. Il peut y avoir des cas où nous pouvons vouloir conserver le décideur humain. Mais il peut y avoir d'autres situations où la vitesse de prise de décision est telle que le fait d'avoir un humain dans la boucle peut être contreproductif. Le trading algorithmique pourrait en être un exemple.
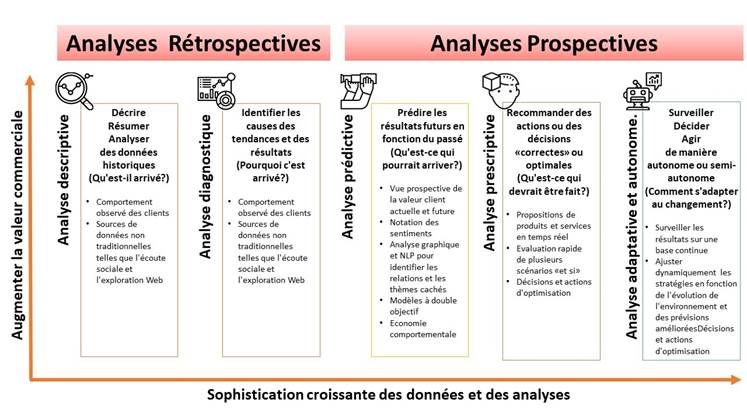
Voici un aperçu de haut niveau des différents types d'analyses. Regardons les outils disponibles pour vous aider à effectuer chacun d'eux.
Les analyses descriptives et diagnostiques reposent généralement sur des outils analytiques qui peuvent gérer la manipulation de grands ensembles de données ou qui aident à visualiser et à interagir avec des informations résumées.
Les exemples:
- SQL
- base de données Oracle ou Oracle DB
- Hadoop / Spark
- Tableau
- QlikView
- Microsoft Access
- SAS R
- Python
- Divers packages statistiques en leur sein.
Les analyses prédictives et prescriptives reposent traditionnellement sur des outils d'analyse dotés de capacités de modélisation mathématique importantes ou de capacités de planification ou de simulation de scénarios.
Les exemples de ces outils
- SAS
- R
- SPSS
- Python
- Outils d'optimisation comme Garrobi, ILOG, RiverLogic, etc.
- Outils de simulation comme Vensim, AnyLogic, STELLA.
- Outils de Machine learning (d'apprentissage automatique) et Deep learning(d'apprentissage en profondeur), comme Scikit, TensorFlow, Caffe, Theano, etc.
- Outils de traitement du langage naturel comme NLTK ou Natural Language Tool Kit ou OpenNLP.
Dans cette section, nous avons parlé de cinq différents types d'analyses que vous pouvez utiliser pour analyser les données. L'analyse descriptive vous aide à comprendre l'état actuel du problème et à répondre à la question, que s'est-il passé? L'analyse diagnostique vous aide à comprendre pourquoi cela s'est produit ou les causes sous-jacentes des données observées. L'analyse prédictive vous aide à comprendre ce qui pourrait arriver à l'avenir dans certaines conditions. L'analyse prescriptive vous aide à comprendre la bonne marche à suivre aujourd'hui pour répondre aux préoccupations futures. L'analyse adaptative et autonome vous aide à répondre à la question de savoir comment s'adapter en permanence au changement. Nous avons également examiné de très haut niveau les outils disponibles pour vous aider à effectuer ces analyses. Plus tard dans le cours, nous examinerons de plus près ce que font certains de ces outils et comment ils apportent de la valeur.
 3 Data Management avec un Data Lab
3 Data Management avec un Data Lab
3.1 Problèmes de gestion des données
Les problèmes les plus courants rencontrés par les entreprises concernant la gestion des Big data comprennent:
 le manque d'investissements informatiques tels que l'achat d'outils analytiques modernes pour gérer des données et des analyses plus volumineuses avec une meilleure efficacité.
le manque d'investissements informatiques tels que l'achat d'outils analytiques modernes pour gérer des données et des analyses plus volumineuses avec une meilleure efficacité. incapable d'analyser les big data en raison de sa complexité qui amène les entreprises à plus de confusion
incapable d'analyser les big data en raison de sa complexité qui amène les entreprises à plus de confusion le manque d'analystes de données et d'autres professionnels de l'informatique pour aider à interpréter les données
le manque d'analystes de données et d'autres professionnels de l'informatique pour aider à interpréter les données- incapable d' intégrer les big data dans les analyses et de les appliquer pour une meilleure optimisation des stratégies de l'entreprise
3.2 Qu’est-ce qu’un Data Lab ?
Comme son nom l’indique, le Data Lab est un véritable laboratoire de la donnée. Pourquoi ? Car c’est un espace exclusivement dédié à l’expérimentation et à la qualification « fonctionnelle » des différentes données de l’entreprise. En effet, il permet d’explorer ses jeux de données, de les traiter, mais aussi de mettre à l’épreuve des algorithmes de Machine Learning.
Pour l’imaginer, le Data Lab est semblable à une startup, agile et en constante évolution, mais qui prendrait place au sein même de l’entreprise. Il permet ainsi de devenir davantage « data centric », sans pour autant chambouler toute l’organisation d’une entreprise.
3.3 Les enjeux d’un Data Lab
Pour mettre en production un projet de Data Science ou d’intelligence artificielle, l’ingrédient clé est une vision stratégique claire, partagée et soutenue par l’ensemble de l’entreprise. Si cela paraît évident, c’est pourtant, ce qui fait défaut dans la majorité des cas. Voilà pour la théorie, mais dans la pratique, de quoi a-ton besoin ? D’un Data Lab.
Sa création est essentielle à la réussite d’un tel projet. L’enjeu même d’une telle structure est de tirer profit de ses données, de les transformer en valeur ajoutée. Pour cela, le Data Lab permet de définir les cas d’usage les plus adaptés à l’entreprise, qu’il s’agisse de réduction de taux d’attrition ou de détection de fraudes.
3.4 Comment mettre en place un Data Lab ?
Pour mettre en place un Data Lab, il faut tout d’abord avoir défini ses objectifs au préalable. En effet, sans alignement de l’ensemble de l’entreprise, le projet aura moins de chance d’atteindre la mise en production.
Après avoir identifié les ressources nécessaires, la mise en place d’une équipe est ensuite primordiale, et ce n’est pas une mince affaire. Il faudra alors privilégier les profils techniques experts dans leur domaine (l’administrateur système, le Data Architect, le Data Scientist, le Data Engineer et le Data Analyst) auquel s’ajoutent le Product Owner qui apportera la vision sur le produit et les profils métiers qui apporteront leur connaissance sur les problématiques business.
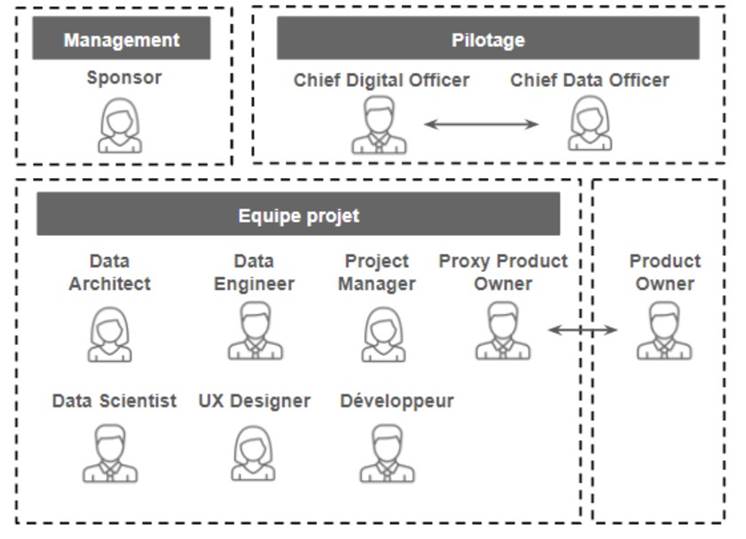
- L'Administrateur Système, qui permettra la mise en place de l'infrastructure IT.
- Le Data Architect qui met en place les choix d’architecture du Data Lab.
- Le Data Scientist qui va être en charge de la conception des algorithmes et modèles analytiques et prédictifs.
 Le Data Engineer qui assure la mise en place des différentes séquences de traitement de la donnée (on parlera de pipeline de données) jusqu'à leur mise en production.
Le Data Engineer qui assure la mise en place des différentes séquences de traitement de la donnée (on parlera de pipeline de données) jusqu'à leur mise en production. Les Experts Métiers qui auront un oeil avisé sur les données dont ils auront besoin avec une connaissance des problématiques business, ils doivent être impliqués dès le début du projet et être des sponsors de ce dernier et de votre Data Lab !
Les Experts Métiers qui auront un oeil avisé sur les données dont ils auront besoin avec une connaissance des problématiques business, ils doivent être impliqués dès le début du projet et être des sponsors de ce dernier et de votre Data Lab ! Le Product Owner qui aidera les Experts Métier à formaliser leurs besoins et supervisera le développement du produit (ou de la solution) intégrant les modèles analytiques.
Le Product Owner qui aidera les Experts Métier à formaliser leurs besoins et supervisera le développement du produit (ou de la solution) intégrant les modèles analytiques. Le Business / Data Analyst qui permettra de mettre sous forme de tableaux de bord et graphiques les résultats concluant des POCs et des projets en production.
Le Business / Data Analyst qui permettra de mettre sous forme de tableaux de bord et graphiques les résultats concluant des POCs et des projets en production.
3.5 Différents typologies en fonction du pourcentage des rôles
3.5.1 IT-centrique
Parfois, l'embauche de scientifiques des données n'est pas une option, et vous devez tirer parti des talents qui sont déjà en interne. Le principal rôle de l'analytique et du leadership serait un «traducteur commercial», généralement appelé chef de l'analyse (CAO) ou chef des données (CDO). Ce dernier terme devient progressivement redondant à mesure que la plupart des processus de données sont remodelés vers l'analyse prédictive. Cette personne doit être capable de diriger l'initiative. Nous examinerons plus en détail la position ci-dessous.
Tout le reste - préparation des données, modèles de formation, création d'interfaces utilisateur et déploiement de modèles au sein d'une infrastructure informatique d'entreprise - peut être largement géré par le service informatique (si votre organisation dispose déjà d'un service informatique interne pleinement fonctionnel). Cette approche est assez limitée, mais elle peut être réalisée en utilisant des solutions
MLaaS(Machine learning as a Service). Des environnements comme Azure Machine Learning ou Amazon Machine Learning sont déjà équipés d'interfaces utilisateur accessibles pour nettoyer les ensembles de données, former des modèles, les évaluer et déployer.
Azure Machine Learning, par exemple, prend en charge ses utilisateurs avec une documentation détaillée pour un seuil d'entrée bas. Cela permet une formation rapide et un déploiement précoce des modèles même sans un expert en données à bord.
En revanche, les solutions MLaaS présentent leurs limites en termes de méthodes d'apprentissage machine et de coût. Toutes les opérations, du nettoyage des données à l'évaluation du modèle, ont leurs prix distincts. Et étant donné que le nombre d'itérations pour former un modèle efficace ne peut pas être estimé à l'avance, travailler avec les plateformes MLaaS entraîne une certaine incertitude budgétaire.
Avantage du IT-centrique:
- L'infrastructure informatique est fournie et maintenue par un service externe - data analytiques plateforme externe comme AWS
- Des spécialistes internes peuvent être formés pour exploiter davantage le potentiel d'analyse prédictive
 La gestion inter-silos est réduite car toutes les opérations se déroulent au sein du service informatique
La gestion inter-silos est réduite car toutes les opérations se déroulent au sein du service informatique- Moins de temps de mise sur le marché pour des tâches d'apprentissage automatique relativement simples nécessitant seulement un ou plusieurs modèles
Inconvénient du IT-centrique:
 Méthodes d'apprentissage machine et procédures de nettoyage des données sont limitées par la capacité fournie.
Méthodes d'apprentissage machine et procédures de nettoyage des données sont limitées par la capacité fournie.- Le model training, les tests et la prédiction doivent être payés par nombres d'utilisation et la quantité de données. Cela entraîne une incertitude quant au coût éventuel par prévision, car le nombre d'itérations nécessaires ne peut pas être estimé à l'avance.
3.5.2 Structure intégrée
Grâce à la structure intégrée, une équipe de science des données se concentre sur la préparation des ensembles de données et la formation sur les modèles, tandis que les spécialistes informatiques prennent en charge les interfaces et l'infrastructure permettant aux data scientists de déployer les modèles. Combiner l'expertise de l'apprentissage automatique avec les ressources informatiques est l'option la plus viable pour des opérations d'apprentissage automatique constantes et évolutives.
Contrairement à l'approche IT-centrique, la méthode intégrée nécessite d'avoir un data scientist expérimenté dans une équipe et un effort de recrutement élaboré au préalable. Cela garantit une meilleure flexibilité opérationnelle en termes de techniques disponibles. Outre des services de bout en bout et pourtant limités, vous pouvez tirer parti d'outils et de bibliothèques d'apprentissage machine plus approfondis - comme Tensor Flow ou Theano - qui sont conçus pour les chercheurs et les experts ayant une formation en science des données. Avec cette répartition des efforts, vous pouvez résoudre des problèmes commerciaux très spécifiques et choisir entre des solutions ML en tant que service et personnalisées.
Avantage du modèle structure intégrée:
- Les scientifiques des données se concentrent sur l'innovation
- Exploiter pleinement le potentiel des applications ML en tant que service et personnalisées
- Commencez avec un ou deux spécialistes des données, puis formez et embarquez plus d'experts locaux
 Utilisation de combinaisons de modèles personnalisés (modèles d'ensemble) qui produisent de meilleures prévisions
Utilisation de combinaisons de modèles personnalisés (modèles d'ensemble) qui produisent de meilleures prévisions
Inconvénient du modèle structure intégrée:
- Une infrastructure informatique est requise en cas d'utilisation de ML personnalisé
- La gestion de silos croisés demande des efforts considérables
- Investissements importants dans l'acquisition de talents en data science
- Défis de l'engagement et de la rétention des talents en data science
3.5.3 Département spécialisé en Data science
Pour réduire les efforts de gestion et créer un cadre de machine learning complet, vous pouvez exécuter l'intégralité du flux de travail de machine learning au sein d'un service indépendant de data science. Cette approche entraîne le coût le plus élevé. Toutes les opérations, du nettoyage des données et de la formation des modèles à la création d'interfaces frontales, sont réalisées par une équipe dédiée de science des données. Cela ne signifie pas nécessairement que tous les membres de l'équipe doivent avoir une formation en science des données, mais ils doivent acquérir des compétences en infrastructure technologique et en gestion de services.
Un modèle spécialisé aide à traiter des tâches complexes de science des données qui incluent la recherche, l'utilisation de plusieurs modèles de ML adaptés à divers aspects de la prise de décision ou de multiples services soutenus par le ML. Dans le cas des grandes organisations, des équipes spécialisées en data science peuvent compléter différentes unités commerciales et opérer dans leurs domaines spécifiques d'intérêt analytique.
La plupart des entreprises innovantes axées sur l'IA ont des équipes spécialisées en science des données. De toute évidence, étant conçus sur mesure et câblés pour des tâches spécifiques, ils sont tous très différents.
La structure de l'équipe d'Airbnb Data Science est l'une des plus intéressantes.
Avantage du modèle spécialisé:
- Gestion centralisée de la science des données et capacités accrues de résolution de problèmes
- Réaliser le plein potentiel des applications ML en tant que service et personnalisées
- Résoudre des problèmes de prédiction complexes qui nécessitent une recherche approfondie ou la construction d'usines de modèles segmentés (qui fonctionnent automatiquement sur différents segments et unités commerciales)
 Mise en place d'un terrain de jeu de science des données complet pour favoriser l'innovation
Mise en place d'un terrain de jeu de science des données complet pour favoriser l'innovation- Meilleure scalabilité
Inconvénient du modèle spécialisé:
- Construire et maintenir une infrastructure informatique complexe
- Investissements importants dans l'acquisition de talents en science des données
- Défis de l'engagement et de la rétention des talents en science des données

Quelle que soit la structure que vous choisissez pour commencer à constituer des équipes de science des données, il est essentiel d'avoir le bon talent.
3.5.4 Compétence requise par rôle:
1. Data scientist:
Les scientifiques des données sont des personnes possédant une combinaison de compétences en codage et en statistiques qui travaillent à rendre les données utiles de diverses manières. Il y a principalement deux types de data scientists:
Data scientist du type A:
Ce type vise principalement à donner un sens aux données ou à les utiliser d'une manière assez statique. Un Data Scientist du type A est très similaire à un statisticien (et peut en être un) mais connaît tous les détails pratiques du travail avec des données qui ne sont pas enseignées dans le programme de statistiques: nettoyage des données, méthodes pour traiter des ensembles de données très volumineux, visualisation, profonde connaissance d'un domaine particulier, bonne rédaction des données, etc.
Data scientist du type B:
Le scientifique des données de type B s'intéresse principalement à l'utilisation des données "en production".
Ils construisent des modèles qui interagissent avec les utilisateurs, servant souvent des recommandations (produits, personnes que vous connaissez peut-être, annonces, films, résultats de recherche). Ces gens utilisent des données dans la production.
En résumé, un data scientist est une personne qui résout les tâches métier à l'aide des techniques d'apprentissage automatique et d'exploration de données. Si cela est trop flou, le rôle peut être limité à la préparation et au nettoyage des données avec une formation et une évaluation plus poussées du modèle.
Compétences préférées: R, SAS, Python, Matlab, SQL, noSQL, Hive, Pig, Hadoop, Spark
2. Chief Analytics Officer/Chief Data Officer
CAO, un «traducteur commercial», comble le fossé entre la science des données et l'expertise du domaine agissant à la fois comme un visionnaire et un responsable technique.
Compétences préférées: Data science et analytiques, compétences en programmation, expertise dans le domaine, leadership et capacités visionnaires
3. Data analyst
Le rôle d'analyste de données implique des activités appropriées de collecte et d'interprétation des données. Un analyste s'assure que les données collectées sont pertinentes et exhaustives tout en interprétant également les résultats de l'analyse. Certaines entreprises, comme IBM ou HP, exigent également que les analystes de données possèdent des compétences en visualisation pour convertir des nombres aliénants en informations tangibles par le biais de graphiques.
Compétences préférées: R, Python, JavaScript, C/C++, SQL
4. Business analyst
Un business analyst réalise essentiellement les fonctions d'un CAO mais au niveau opérationnel. Cela implique de convertir les attentes des entreprises en analyse de données. Si votre spécialiste des données de base manque d'expertise dans le domaine, un analyste d'entreprise comble ce gouffre.
Compétences préférées: data visualization, business intelligence, SQL
5. Data architect
Ce rôle est essentiel pour travailler avec de grandes quantités de données (vous l'avez deviné, Big Data). Cependant, si vous ne comptez pas uniquement sur les plates-formes cloud MLaaS, ce rôle est essentiel pour stocker les données, définir l'architecture de la base de données, centraliser les données et garantir l'intégrité entre les différentes sources. Pour les grands systèmes distribués et les grands ensembles de données, l'architecte est également en charge des performances.
Compétences préférées:SQL, noSQL, XML, Hive, Pig, Hadoop, Spark
6. Data engineer
Les ingénieurs mettent en œuvre, testent et entretiennent les composants d'infrastructure conçus par les architectes de données. De façon réaliste, le rôle d'un ingénieur et le rôle d'un architecte peuvent être combinés en une seule personne. L'ensemble des compétences est très proche.
Compétences préférées:SQL, noSQL, Hive, Pig, Matlab, SAS, Python, Java, Ruby, C++, Perl
7. Application/data visualization engineer
Fondamentalement, ce rôle n'est nécessaire que pour un modèle spécialisé de science des données. Dans d'autres cas, les ingénieurs logiciels proviennent d'unités informatiques pour fournir des résultats de science des données aux applications auxquelles les utilisateurs finaux sont confrontés. Et il est très probable qu'un ingénieur d'application ou d'autres développeurs d'unités frontales supervisent la visualisation des données de l'utilisateur final.
Compétences préférées:programming, JavaScript (for visualization), SQL, noSQL
3.6 Comment outiller le Data Lab ?
Une fois que l'équipe soit construite, il est indispensable de construire l'infrastructure des données en choisissant attentivement la technologie associée.
Certaines questions sont à poser avant de faire le choix:
- D’où viennent vos sources de données ?
- Comment les regrouper ?
- Quelles sont les difficultés liées à leur utilisation ?
- Structurées ou non?
- Sont-elles conformes aux réglementations en vigueur?
Source classique:
- Les différentes données de votre SI constituent la principale (et la plus évidente) source à exploiter.
 Les logs que les utilisateurs laissent lors de l’utilisation de vos applications, de vos logiciels ou lorsqu'ils naviguent sur votre site internet sont également une importante source de données utilisable pour optimiser votre produit, vos ventes… les mesures de divers capteurs (IoT)
Les logs que les utilisateurs laissent lors de l’utilisation de vos applications, de vos logiciels ou lorsqu'ils naviguent sur votre site internet sont également une importante source de données utilisable pour optimiser votre produit, vos ventes… les mesures de divers capteurs (IoT)- Certaines entreprises spécialisées dans la revente de données peuvent aussi constituer une source de données intéressantes avec des informations telles que : données géographiques, socioprofessionnelles, habitudes de consommation…
3.7 Centraliser les données disponibles
![]() “
“
Un des prérequis nécessaire est de faciliter l'accès aux données pour les data scientists
3.7.1 mettre en place un Data Lake
Le principe du Data Lake (ou lac de données) est assez simple, toutes vos données sont regroupées et accessibles en un seul et même endroit. L'avantage considérable d'un Data Lake, comparativement à un Data Warehouse (ou entrepôt de données), réside d'une part dans sa capacité à croiser et enrichir des données beaucoup plus simplement, tout au long du projet, et à en accroître leur disponibilité (même en cas de panne) grâce à un mécanisme de réplication.
3.7.2 L'exploitation d'un Data Lake par le Data Lab implique l'utilisation d'un certain nombre de technologies :
ETL (Extract - Transform - Load) par batch (lot) ou streaming (continu, temps réel)
- SQOOP
- Spark
- Kafka Stream
- Talend
Statistiques et modélisation
- Spark
- Java
- Python
- R
Format de stockage des fichiers
- Avro
- Parquet
- ORC
Technologies liées au stockage de données
- Stockage distribué (files system): Hadoop et son système de fichier HDFS
- Stockage avec une base de données (SQL, NoSQL) :
- Cassandra
- Mongo DB
- Elasticsearch
- PostgreSQL
Les technologies de Data Science
- Langages de programmation
- Python
- R
- Scala
- Deep
- Learning
- Tenso Flow
- Keras
- Pytorch
- Environnement de développement (IDE)
- R Studio
- Jupyter Lab
- PyCharm
Comme vous pouvez le constater, la réalisation d’un projet Big Data / IA va impliquer grand nombre technologies disparates et peu intégrées. Leur utilisation va varier en fonction de la composition de votre Data Lab, ce qui va complexifier la chose.
En revanche, il existe des solutions intégrées sur le marché(en Cloud ou pas). En proposant un
environnement unique où ces différentes technologies vont être pré-assemblées et orchestrées les unes avec les autres tout en étant maintenues à jour, ce qui va grandement simplifier leur mise à disposition pour l’ensemble du Data Lab.
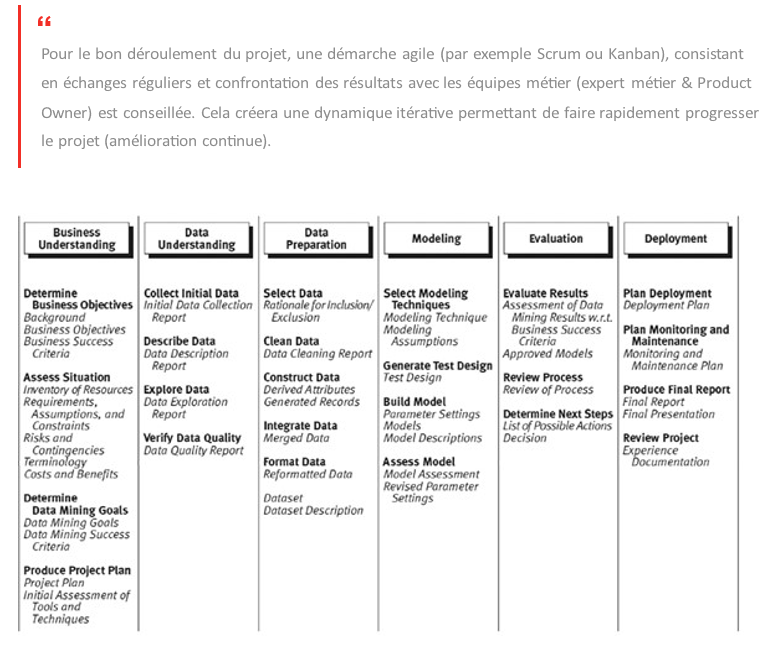
3.8 Méthode CRISP : mode d’emploi
La méthode CRISP (initialement connue comme CRISP-DM) a été au départ développée par IBM dans les années 60 pour réaliser les projets Datamining. Elle reste aujourd’hui la seule méthode utilisable efficacement pour tous les projets Data Science.
La méthode CRISP se décompose en 6 étapes allant de la compréhension du problème métier au déploiement et la mise en production.
1. La compréhension du problème métier
La première étape consiste à bien comprendre les éléments métiers et problématiques que la Data Science vise à résoudre ou à améliorer.
2. La compréhension des données
Cette phase vise à déterminer précisément les données à analyser, à identifier la qualité des données disponibles et à faire le lien entre les données et leur signification d’un point de vue métier. La Data Science étant basée sur les données seules, les problèmes métiers relatifs à des données existantes, qu’elles soient internes ou externes, peuvent ainsi être résolus par la Data Science.
3. La construction du Data Hub
Cette phase de préparation des données regroupe les activités liées à la construction de l’ensemble précis des données à analyser, faite à partir des données brutes. Elle inclut ainsi le classement des données en fonction de critères choisis, le nettoyage des données, et surtout leur recodage pour les rendre compatibles avec les algorithmes qui seront utilisés.
La paramétricité des données numériques et leur recodage en données catégorielles sont extrêmement importantes et à réaliser avec soin afin d’éviter que les algorithmes utilisés donnent des résultats faux dans la phase suivante. Toutes ces données doivent en effet être centralisées dans une base de données structurée et qui porte le nom de Data Hub.
4. La modélisation
C’est la phase de Data Science proprement dite. La modélisation comprend le choix, le paramétrage et le test de différents algorithmes ainsi que leur enchaînement, qui constitue un modèle. Ce processus est d’abord descriptif pour générer de la connaissance, en expliquant pourquoi les choses se sont passées. Il devient ensuite prédictif en expliquant ce qu’il va se passer, puis prescriptif en permettant d’optimiser une situation future.
5. L’évaluation
L’évaluation vise à vérifier le(s) modèle(s) ou les connaissances obtenues afin de s’assurer qu’ils répondent aux objectifs formulés au début du processus. Elle contribue aussi à la décision de déploiement du modèle ou, si besoin est, à son amélioration. A ce stade, on teste notamment la robustesse et la précision des modèles obtenus.
6. Le déploiement
Il s’agit de l’étape finale du processus. Elle consiste en une mise en production pour les utilisateurs finaux des modèles obtenus. Son objectif : mettre la connaissance obtenue par la modélisation, dans une forme adaptée, et l’intégrer au processus de prise de décision.
Le déploiement peut ainsi aller, selon les objectifs, de la simple génération d’un rapport décrivant les connaissances obtenues jusqu’à la mise en place d’une application, permettant l’utilisation du modèle obtenu, pour la prédiction de valeurs inconnues d’un élément d’intérêt.
3.9 L’Expérimentation des données
Il est important d’échanger avec les métiers et d’identifier des "quick wins" simples à transformer. Les initiatives autour de l’IA et du Big Data doivent être guidées par un besoin métier et répondre à une problématique de l’entreprise, sans quoi les projets risquent de ne pas de produire l’effet escompté. Il est important de créer une relation forte entre les métiers et le Data Lab car la finalité du projet sera d’autant plus pertinente et apportera plus rapidement des résultats.
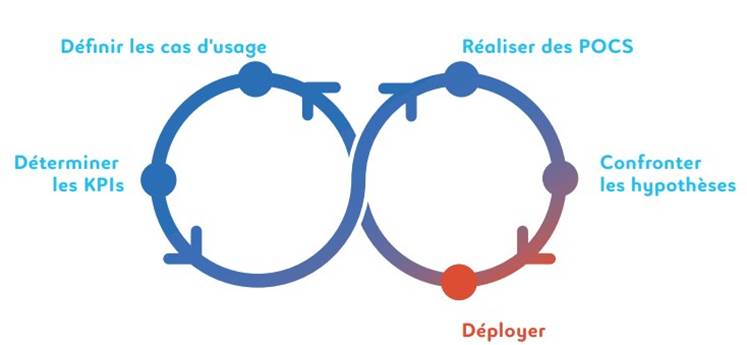
3.9.1 Paradigme
|
1. Imaginer |
2. Bâtir |
3. Exploiter |
|
Faire émerger des cas d'usage et définir des KPIs |
Monter une équipe, une architecture et collecter des données |
POC Tableaux de bord (valeur métiers) |
En résumé, un projet Big data / IA, c’est : 90% de design thinking* pour faire émerger vos cas d'usage
*Le Design Thinking est une approche consistant à appliquer les méthodes et la philosophie utilisées par les designers pour résoudre certains problèmes. Il s'appuie en grande partie sur un processus de co-créativité impliquant des retours de l'utilisateur final.
3.9.2 Comment choisir le cas d'usage
La sélection des cas d'usage va se dérouler de la manière suivante :
Divergence: Faire émerger le plus grand nombre de cas d'usage
Convergence: Identifier les cas d'usage pertinents Identifier les cas d'usage réalisables
Quelques questions sont à considérer pour sélectionner les cas d'usage : Le cas d'usage produit-il une valeur ajoutée métier ? Des KPIs peuvent-ils être définis pour mesurer la valeur métier créée ? Le POC (Proof Of Concept) que je vais réaliser pourra-t-il intégrer des processus métiers opérationnels ?
Autre point à considérer : plutôt que d’adresser une multitude de cas d'usage en même temps, il est préférable de se focaliser sur un ou deux cas d'usage, afin de démontrer rapidement de la valeur et se familiariser avec les nouvelles approches qui seront mises en place.
3.9.3 Le déroulement des POCs
- Compréhension Il est indispensable de travailler avec les Experts Métiers pour comprendre les données vraiment utiles, et déterminer si l'on a besoin d'utiliser des données externes à l'entreprise
(par exemple l'Open Data)
- Exploration Cette étape va permettre de déterminer si les données sont intéressantes et fiables. Elle va mettre en évidence les données manquantes (anomalies, champs vides) et décrire les variables (avec des indicateurs tels que la moyenne, variance, quartile, classe, saisonnalité) nécessaires à l'élaboration de KPIs
une collaboration étroite entre le Data Scientist et le Data Engineer est essentielle et celle-ci se déroule en deux phases :
- Préparation. Le pré-traitement (ou preprocessing), qui consiste dans le nettoyage, l’exploration et surtout la compréhension des données de l’entreprise. Cette partie est souvent assez longue mais essentielle pour que les Data Scientists puissent travailler la donnée.
- Apprentissage. L'algorithmique qui passe par la construction de modèles descriptif ou prédictifs visant à apporter de la valeur ajoutée.
4.Techniques et outils d'analyse des données
4.1 Introduction aux techniques d'analyse de données
Dans cette section, nous allons examiner les différents types d'analyses que vous pouvez effectuer une fois que vous avez identifié le problème ou l'opportunité commerciale, développé une hypothèse et collecté des données pertinentes. Alors que la capacité de traitement continue d'augmenter, il a ouvert la porte à un large éventail d'algorithmes et de techniques de modélisation avancés que les organisations peuvent utiliser pour produire des informations précieuses à partir des données.
Nous avons une grande variété de problèmes commerciaux impliquant l'analyse prédictive, la gestion des données, l'échantillonnage statistique et la conception des enquêtes. Certains sont assez simples, et beaucoup ont été complexes, à travers un large éventail de problèmes commerciaux dans des secteurs tels que les soins de santé, les services financiers, le commerce de détail et la consommation.
Nous discuterons d'une série de techniques analytiques et de leur utilisation dans le monde réel.

Nous allons commencer par parler de l'analyse par grappes(L'analyse de cluster). L'analyse de cluster consiste à regrouper un ensemble d'objets de manière à ce que les objets du même groupe ou cluster soient plus similaires les uns aux autres que ceux des autres clusters. L'analyse de grappes est souvent utilisée dans les études de marché lorsque vous travaillez avec des données de groupes de discussion et d'enquêtes. Une analyse en grappes peut être utilisée pour segmenter une population de consommateurs en groupes de marché afin de mieux comprendre les relations entre les différents groupes de consommateurs. Cette analyse peut aider à répondre à des questions telles que, qui sont mes clients cibles? Comment sont-ils différenciés sur les caractéristiques comportementales, psychographiques et démographiques? Y a-t-il des groupes qui ont des attributs similaires afin que les produits, services, offres de prix puissent être utilisés pour personnaliser les segments?
Passons maintenant à l'analyse de l'arbre de décision(Arbre descriptive analytique). Un outil d'aide à la décision qui utilise un graphique arborescent des décisions et de leurs conséquences possibles. Y compris les résultats des événements fortuits, le coût des ressources et l'utilité. L'analyse de l'arbre de décision est souvent utilisée pour aider les professionnels de la santé à envisager la variation des traitements ainsi que les coûts et les probabilités de réussite de chacun. Par exemple, les prestataires de soins de santé peuvent utiliser cette analyse pour évaluer les options et fournir des traitements plus rentables qui minimisent le risque de réadmission à l'hôpital. Pour analyser un grand nombre de variables dépendantes et indépendantes , nous pourrions utiliser l'analyse factorielle. Ce type d'analyse peut aider à détecter les aspects des variables indépendantes qui sont liés aux variables dépendantes. Lorsque nous recevons les données, des ensembles assez larges, ce qui signifie qu'ils comportaient plus de variables dans les observations ou les enregistrements. Nous avons besoin d'un moyen d'identifier l'ensemble de variables ou d'inducteurs de base qui permettront d'obtenir des informations significatives.
L'analyse factorielle peut aider à identifier ce sous-ensemble réduit de variables, ce qui signifie que certaines de ces variables représentent des relations similaires à celles qui ne sont pas incluses, mais peutêtre d'une manière plus forte.
Machine learning est un type d'intelligence artificielle qui fournit aux ordinateurs la possibilité d'apprendre sans être explicitement programmé pour le faire. Pour les détaillants avant-gardistes, les possibilités deMachine learning avancé sont illimitées. Prenons par exemple une entreprise qui essaie de prédire ce que ses clients vont acheter au printemps prochain. Les algorithmes deMachine learning peuvent déterminer la disponibilité des matériaux auprès de fournisseurs externes, incorporer divers scénarios de chaîne d'approvisionnement. Et recommander la quantité, le prix, le placement en rayon et le canal de marketing qui atteindraient le mieux le consommateur cible dans une zone géographique particulière.
L'analyse de régression est un processus statistique permettant d'estimer les relations entre une variable dépendante et une ou plusieurs variables indépendantes. Les variables sont les éléments d'information. Ce type d'analyse vous aide à comprendre comment la valeur d'une variable dépendante change lorsque l'une des variables indépendantes change Par exemple, une grande compagnie d'assurance souhaite identifier les caractéristiques, notamment la tranche d'âge, le revenu, le sexe, le niveau d'instruction, etc. Des clients qui tendent à faire le plus de réclamations automobiles. Ce type d'analyse peut être utilisé pour évaluer le risque, mais aussi aider à déterminer les prix de divers produits d'assurance automobile.
L'analyse multivariée est l'observation et l'analyse de plus d'une variable de résultat statistique à la fois. Cela comprend souvent comme première analyse de corrélation, qui peut vous aider à comprendre et à visualiser les relations entre des paires de variables. La régression multivariée est une technique qui estime une seule modèle de régression avec plus d'une variable de résultat. Lorsqu'il existe plusieurs variables prédictives dans un modèle de régression multivariée, le modèle est une régression multiple multivariée. Pour comprendre les relations d'efficacité des résultats d'un traitement médical particulier, il peut également être nécessaire de comprendre variables confondantes telles que l'âge, le poids, le sexe ou d'autres médicaments que le patient peut recevoir. Il peut y avoir plusieurs façons d'évaluer les résultats et donc, plus d'une variable dépendante et de plusieurs variables indépendantes.
L'analyse de segmentation divise une large catégorie en sous-ensembles qui ont ou sont perçus comme ayant des caractéristiques, des besoins, des intérêts ou des priorités communs. Souvent, l'analyse de segmentation est utilisée pour mieux comprendre les besoins des clients en plongeant un grand nombre de personnes en petits groupes sur la base d'un schéma logique. La segmentation fournit un mécanisme pratique autour duquel développer des produits, construire des programmes et exécuter des tactiques marketing.

L'analyse des séries chronologiques(Time series) peut être utilisée pour concevoir une méthodologie pour identifier les facteurs affectant la demande des passagers des compagnies aériennes sur les routes en tirant parti des données macroéconomiques, démographiques et autres données externes, au niveau local, étatique et national. De tels modèles peuvent être développés pour produire une route niveau de prévision de la demande totale de voyages en avion. Aide à l'optimisation de la planification des itinéraires et des capacités et à l'identification de nouveaux itinéraires pour l'entrée sur le marché. L'analyse des séries chronologiques comprend des méthodes d'analyse des données collectées au fil du temps pour extraire des statistiques significatives. Cours des actions, volumes de ventes, taux d'intérêt et les mesures de qualité sont tous des exemples typiques. En raison de cette nature séquentielle des données, des techniques statistiques spéciales tenant compte de la nature dynamique des données sont requises.
4.2 Explorer les outils d'analyse de données
La demande de data scientist dans chaque industrie augmente considérablement. Pour le développement de chaque entreprise, il est nécessaire d'évaluer les données que vous collectez. Et les data scientistes ont besoin à la fois des bons outils et des compétences parfaites pour vous permettre de produire de meilleurs résultats avec vos informations.
D'après le rapport Forbes, la Data Science est le meilleur emploi aux États-Unis au cours des trois dernières années consécutives. De plus, selon une étude IBM, la demande de Data Scientist augmentera de 28% d'ici 2020, avec près de trois millions de postes vacants pour professionnels de la science des données.
La science des données est un concept qui rassemble les statistiques, l'analyse des données et leurs stratégies connexes pour comprendre et analyser les merveilles réelles avec les données. Elle fait appel à des théories et des techniques issues de divers domaines dans les vastes régions de la statistique, des mathématiques, de l'informatique et des sciences de l'information.
Avec l'avancement de l'apprentissage automatique, la science des données gagne en popularité. Pour comprendre et devenir data scientist, vous devez apprendre au moins un langage de programmation (même si en savoir plus est avantageux pour les demandeurs d'emploi). Vous avez plusieurs options pour choisissez parmi.
La science des données est un domaine passionnant dans lequel travailler, combinant des compétences quantitatives et des statistiques avancées avec des capacités de programmation dans le monde réel.
Voyons maintenant quelques principaux langages de programmation qu'un scientifique des données devrait maîtriser en 2020.
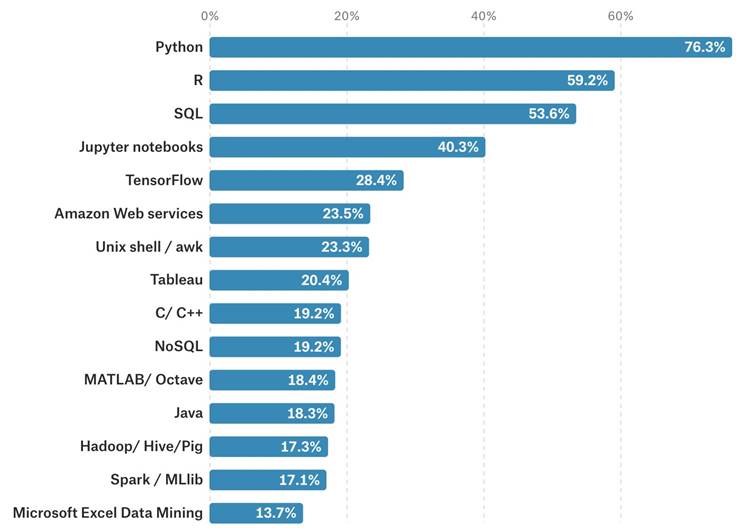
4.2.1 SQL
 L'acronyme SQL signifie de Structured Query Language . Il s'agit du langage standard pour de
L'acronyme SQL signifie de Structured Query Language . Il s'agit du langage standard pour de
nombreux systèmes de gestion de bases de données relationnelles et de manipulation de données. SQL est souvent utilisé pour interroger, insérer, mettre à jour et modifier des données. un niveau de base SQL est une méthode de communication entre vous et la base de données. L'une des grandes choses à propos de SQL est qu'il est composé d'instructions qui sont des mots descriptifs. En d'autres termes, la plupart des commandes utilisées dans SQL sont assez faciles à interpréter par rapport à de nombreux autres langages informatiques. Cela rend SQL, en tant que langage, très facile à comprendre et à apprendre. Cependant, il est important de comprendre que SQL est un langage non procédural. Cela signifie que vous ne pourrez pas écrire d'applications complètes avec lui, mais ce que vous pouvez faire est d'interagir et de communiquer avec les données. Cela rend le langage relativement simple, mais aussi très puissant. Lorsque vous pensez à SQL, il vous suffit de penser aux données.
SQL est une question de données. SQL est vraiment utilisé pour trois choses. Il est utilisé pour lire et récupérer des données, donc les données sont souvent stockées dans une base de données, et vous voulez les récupérer ou les lire. Et vous pouvez utiliser SQL comme un moyen de être un traducteur pour cela. SQL est également utilisé comme un moyen d'écrire des données dans une base de données. Donc, si vous devez écrire des données dans une table ou insérer de nouvelles données, vous pouvez utiliser SQL comme moyen de le faire. Et enfin, c'est utilisé pour mettre à jour et insérer de nouvelles données. Comme vous pouvez le voir, SQL a une conception très simple, à droite. Il est très contenu dans ce qu'il est capable de faire, à savoir lire, écrire et mettre à jour des données. beaucoup de gens qui sont capables d'utiliser ce langage.
Nous avons besoin d'un moyen d'aller chercher ces données. SQL est vraiment fondamental dans la science des données parce que vous ne pouvez vraiment pas commencer à construire des modèles ou faire des prédictions avant d'avoir les données. SQL est le moyen d'aller dans une base de données et d'obtenir ceci Les scientifiques des données peuvent également l'utiliser pour créer leur propre table ou environnement de test. Supposons que vous ayez construit un modèle et que vous souhaitiez le déployer et que vous souhaitiez l'ajouter à nouveau dans la table. Vous devrez peut-être créer le vôtre. table ou environnement de test pour ajouter cela. Une chose qui n'est pas unique avec le scientifique des données, ou d'autres personnes utilisant SQL, est que souvent vous combinez plusieurs tables ensemble et beaucoup de fois cela conduit à des requêtes un peu plus complexes. écrit pour l'analyse. Les scientifiques des données, bien que la principale façon d'utiliser SQL est vraiment de pouvoir récupérer leurs données pour analyse, ils pourraient faire une petite partie de l'analyse en utilisant SQL. Cependant, la principale chose qu'ils utilisent SQL est pour la récupération de données. Encore une fois, vous pouvez penser à SQL comme interprète entre vous et la base de données. La façon dont vous écrivez une partie de la syntaxe pour SQL dépendra du système de gestion de base de données relationnelle avec lequel vous interagissez. En étendant notre analogie, vous pouvez considérer cela comme l'accent ou peut-être comme le dialecte. SQL est capable de le traduire pour vous, mais parfois vous devez le modifier un peu en fonction du système de gestion de base de données que vous utilisez. Ici, j'ai énuméré quelques-uns des plus populaires, SQL Server, PostgreSQL, MySQL.
4.2.2 Python
 Dans cette section, nous allons examiner le rôle que Python joue dans la science
Dans cette section, nous allons examiner le rôle que Python joue dans la science
des données et l'analyse. Python est un langage de programmation open source à usage général qui peut être utilisé pour tout, de la création d'applications Web et de programmes d'entreprise à l'analyse sur de grandes quantités Python est populaire car il est librement disponible à utiliser, met l'accent sur la lisibilité du code, et il est facile pour les nouveaux arrivants d'apprendre. En outre, il est populaire en raison de sa convivialité et de sa capacité à s'intégrer à une variété de programmes, d'outils et sites Web. Python est devenu l'un des langages les plus populaires pour la gestion et l'analyse des données. Aujourd'hui, Python est largement utilisé par les startups et les sociétés de technologie pour intégrer des analyses dans leurs produits, et par les scientifiques des données pour gérer et analyser rapidement de grandes quantités de données. Python dispose d'un ensemble d'outils appelé Python Data Analytics Stack qui répondent à chaque étape du flux de travail d'analyse. Ces outils sont assemblés dans des bibliothèques Python, qui sont des collections de morue e qui sont faciles à utiliser. Bien que les noms de ces bibliothèques spécifiques puissent changer, voici quelques exemples de bibliothèques courantes pour la science des données. Pandas pour l'importation et l'évaluation des données, y compris l'analyse des contours et le nettoyage des données, ainsi que des statistiques récapitulatives. NumPY et SciPy pour effectuer des opérations matricielles, mathématiques et scientifiques extrêmement rapides. Statsmodels pour adapter un large éventail de modèles statistiques aux données. Scikit-Learn en appliquant des techniques d'apprentissage automatique telles que le clustering, la réduction de la dimensionnalité, les forêts aléatoires et la régression logistique. Matplotlib, Seaborn et Bokeh pour produire des visuels attrayants. Et enfin, Apache Spark, pour traiter des données à grande échelle sur un cluster d'ordinateurs. En plus de la science des données normale et des données numériques, Python possède des bibliothèques qui peuvent également gérer des données non structurées comme du texte et des images. Pour par exemple, NLTK, Spacy et Gensim traitent les données de texte. OpenCV manipule et analyse les images. BeautifulSoup et Scrapy font le web scraping e Python peut interagir avec des outils comme Caffe pour utiliser des techniques d'apprentissage approfondi sur de puissantes machines compatibles GPU pour un apprentissage automatique de pointe sur les images, le son et le texte. Et Flask ou Django pour la création de sites Web et de services Web pouvant intégrer des modèles d'apprentissage automatique accessible via Internet.
Nous avons décrit certaines des capacités de Python, mais la grande question est, pourquoi Python?
Notre modèle et nos capacités statistiques sont plus étendus, plus avancés. Lorsque Python brille vraiment, c'est lorsque les données ne sont pas structurées ou que les analyses doivent être intégrées dans d'autres programmes ou applications. Parce que Python est un langage de programmation à usage général, il était facile pour construire des bibliothèques extrêmement efficaces pour traiter toutes sortes de données et interagir avec la plupart des principaux outils de Big Data tels que Hadoop ou Apache Spark. Nous évaluons quelles données principales outil à utiliser en fonction des besoins du client. Je vais souligner quelques exemples d'utilisation de Python. Premièrement, il existe des projets qui utilisent le traitement du langage naturel. Par exemple, vous avez entendu décrire notre travail pour aider un grand client bancaire à comprendre les commentaires qu'il a reçus de ses clients via les canaux de support client, ainsi que les médias sociaux. Nous utilisons Python pour gratter les données, les analyser et les comprendre, puis décrire les cu le sentiment de stomer qui y règne est de mieux prioriser les problèmes que la banque doit résoudre pour améliorer la satisfaction de la clientèle.
C'était un bon exemple de la raison pour laquelle Python a été choisi, non seulement parce qu'il nous permettait de traiter toutes les données à volume élevé, mais aussi parce que le client utilisait Python et voulait du code déployable qui pouvait être conservé après la fin de l'engagement. Finalement, nous avons pu leur fournir des modèles pour prévoir les défaillances de la pompe deux jours avant une défaillance réelle. Assez de temps pour effectuer la maintenance et économiser sur les remplacements coûteux de la pompe. Parfois, le choix de l'outil d'analyse approprié peut sembler intimidant car il y a tellement d'options. Python est un excellent choix car il gère de nombreux cas d'utilisation de la science des données, des simples statistiques descriptives aux modèles statistiques, en passant par l'apprentissage automatique complexe et l'informatique distribuée intégrée dans des applications Web dynamiques. Python est facile à utiliser car il a été conçu pour être facile pour les programmeurs. afin que la courbe d'apprentissage ne soit pas trop abrupte. Si vous ne l'avez pas encore essayé, cela vaut la peine d'être exploré. Dans cette section, nous avons discuté du rôle de Python dans les données et l'analyse Python est gratuit, facile à utiliser, rapide et utile pour les tâches d'analyse de données simples et complexes.
5. Une brève introduction à SQL
Pourquoi devrions-nous nous préoccuper de SQL? Les entreprises doivent garder une trace de beaucoup de données, et la seule façon pratique de le faire est de stocker les données est un certain type de base de données. Si vous devenez analyste de données pour l'entreprise monde, d'une manière ou d'une autre, vous allez devoir trouver comment extraire des données de ces bases de données afin de faire tout type d'analyse. Ce chapitre est conçu pour vous aider à apprendre de haut niveau comment le faire et nous aurons un module dédié qui vous guidera plus en détail dans le monde SQL.
Dans de nombreuses entreprises axées sur la technologie, la seule façon d'extraire des données d'une base de données est d'écrire vos propres requêtes SQL, qui sont des lignes structurées de code informatique qui extraient des données. Dans d'autres entreprises plus grandes et plus traditionnelles, il y a des personnes dans l'entreprise qui pourraient extraire les données pour vous, mais vous devez faire une demande formelle pour qu'elles écrivent, exécutent et interrogent. Et cela peut prendre des jours ou des semaines pour qu'elles répondent à votre demande, surtout si beaucoup d'autres personnes demandent également des requêtes. Pour cette raison, les entreprises sont très désireuses d'embaucher des analystes qui peuvent non seulement analyser les données, mais qui savent comment obtenir les données en premier lieu.
Nous avons mentionné plus tôt que SQL est le langage utilisé pour extraire des données de types spécifiques de bases de données appelées bases de données relationnelles. Les bases de données relationnelles sont la référence pour les bases de données qui stockent des données commerciales hautement organisées et structurées - base de données relationnelle . Il existe également de nouvelles classes de bases de données spécialement conçues pour les données qui sont collectées à un rythme extrêmement rapide, telles que les données GPS ou biocapteurs, ou les données non structurées qui ne correspondent pas bien aux formats hautement prescrits, tels que les tweets ou les textes. Toutefois, bien que ces bases de données soient certainement susceptibles de gagner en popularité à l'avenir, elles ne représentent actuellement qu'une très petite fraction du marché des bases de données.
Dans ce chapitre nous présenterons de manière brève à MySQL, qui est une marque ou une plate-forme particulière de base de données relationnelle. Il existe de nombreuses plates-formes de base de données relationnelles, notamment Oracle, Microsoft, SQL Server, DB2, SQLite, Microsoft Access et PostgreSQL. Nous avons choisi de concentrer sur MySQL.
5.1 Qu'est-ce que c'est MySQL?
![]() “
“
Résumé: Cette section vous aide à répondre à la question: qu'est-ce que MySQL? Et donnez-vous les raisons pour lesquelles MySQL est la base de données open source la plus populaire au monde.
Pour comprendre MySQL, vous devez d'abord comprendre la base de données et SQL. Si vous connaissez déjà la base de données et SQL, vous pouvez passer à la section Qu'est-ce que MySQL.
5.1.1 Introduction à la base de données
Vous traitez les données tous les jours.
 Lorsque vous souhaitez écouter vos chansons préférées, vous ouvrez votre playlist depuis votre smartphone. Dans ce cas, la playlist est une base de données.
Lorsque vous souhaitez écouter vos chansons préférées, vous ouvrez votre playlist depuis votre smartphone. Dans ce cas, la playlist est une base de données.- Lorsque vous prenez une photo et la téléchargez sur votre compte sur un réseau social comme Facebook, votre galerie de photos est une base de données.
- Lorsque vous naviguez sur un site de commerce électronique pour acheter des chaussures, des vêtements, etc., vous utilisez la base de données du panier.
Les bases de données sont partout. Alors qu'est-ce qu'une base de données? Par définition, une base de données n'est qu'une collection structurée de données .
Les données relatives les unes aux autres par nature, par exemple, un produit appartenaient à une catégorie de produits et associées à plusieurs balises. Par conséquent, nous utilisons le terme base de données relationnelle.
Dans la base de données relationnelle, nous modélisons des données comme les produits, les catégories, les balises, etc., à l'aide de tableaux. Un tableau contient des colonnes et des lignes. C'est comme une feuille de calcul.
Une table peut être liée à une autre table à l'aide d'une relation, par exemple, des relations un-à-un et un-àplusieurs.
Parce que nous traitons une quantité importante de données, nous avons besoin d'un moyen de définir les bases de données, les tables, etc., et de traiter les données plus efficacement. De plus, nous voulons transformer les données en informations.
Et c'est là que SQL vient jouer.
5.1.2 SQL - le langage de la base de données relationnelle
![]() “
“
SQL signifie le langage de requête structuré. ( structured query language en anglais.)
SQL est le langage standardisé utilisé pour accéder à la base de données.
ANSI / SQL définit la norme SQL. La version actuelle de SQL est SQL: 2016. Chaque fois que nous nous référons à la norme SQL, nous entendons la version SQL actuelle.
SQL contient trois parties:
1. Le langage de définition des données comprend des instructions qui vous aident à définir la base de données et ses objets, par exemple, les tables, les vues, les déclencheurs, les procédures stockées, etc.
2. Le langage de manipulation des données contient des instructions qui vous permettent de mettre à jour et d'interroger des données.
3. Le langage de contrôle des données vous permet d'accorder les autorisations à un utilisateur pour accéder à des données spécifiques dans la base de données.
5.1.3 MySQL
My est le nom de la fille du co-fondateur de MySQL, Monty Widenius.
Le nom de MySQL est la combinaison de My et SQL, MySQL.
MySQL est un système de gestion de base de données qui vous permet de gérer des bases de données relationnelles. Il s'agit d'un logiciel open source soutenu par Oracle. Cela signifie que vous pouvez utiliser MySQL sans payer un sou. De plus, si vous le souhaitez, vous pouvez modifier son code source en fonction de vos besoins.
Même si MySQL est un logiciel open source, vous pouvez acheter une version de licence commerciale auprès d'Oracle pour obtenir des services d'assistance premium.
MySQL est assez facile à maîtriser par rapport à d'autres logiciels de base de données comme Oracle Database ou Microsoft SQL Server.
MySQL peut fonctionner sur différentes plateformes UNIX, Linux, Windows, etc. Vous pouvez l'installer sur un serveur ou même sur un bureau. De plus, MySQL est fiable, évolutif et rapide.
La façon officielle de prononcer MySQL est My Ess Que Ell, pas My Sequel. Cependant, vous pouvez le prononcer comme bon vous semble, peu importe?
Si vous développez des sites Web ou des applications Web, MySQL est un bon choix. MySQL est un composant essentiel de la pile LAMP, qui comprend Linux, Apache, MySQL et PHP.
5.2 Installez MySQL
5.2.1 Télécharger MySQL Installer
Si vous souhaitez installer MySQL sur l'environnement Windows, l'utilisation du programme d'installation de MySQL est le moyen le plus simple. Le programme d'installation de MySQL vous fournit un assistant facile à utiliser qui vous aide à installer MySQL avec les composants suivants:
- Serveur MySQL
- Tous les connecteurs disponibles
- MySQL Workbench avec des exemples de modèles de données
- Notificateur MySQL
- Outils pour Excel et Microsoft Visual Studio
- Exemples de bases de données MySQL
- Documentation MySQL
Pour télécharger le programme d'installation de MySQL, accédez au lien suivant http://dev.mysql.com/downloads/installer/ . Il existe deux fichiers d'installation (NB. vous pouvez directement télécharger la dernière
![]()
version qui peut être différent de la version 8.0.20 indiqué dans la capture d'écran suivante):
- Si vous vous connectez à Internet pendant l'installation de MySQL, vous pouvez choisir la version d'installation en ligne mysql-installer-web-community- version .exe.
5.2.2 Installer MySQL via MySQL Installer
Pour installer MySQL à l'aide du programme d'installation MySQL, double-cliquez sur le fichier d'installation MySQL et suivez les étapes ci-dessous:
Etape01 : Exécuter le programme d'installation
Etape02 : Choisissez la configuration par défaut
Etape03 : Vérification des exigences
Etape04 : Progression de l'installation: MySQL Installer télécharge tous les produits sélectionnés. Cela prendra un certain temps, selon les produits que vous avez sélectionnés et la vitesse de votre connexion Internet.
Etape05 : Présentation de la configuration
Etape05.1 : Mot de passe à configurer - MySQL Root Password
Etape06 : Configuratoin Production
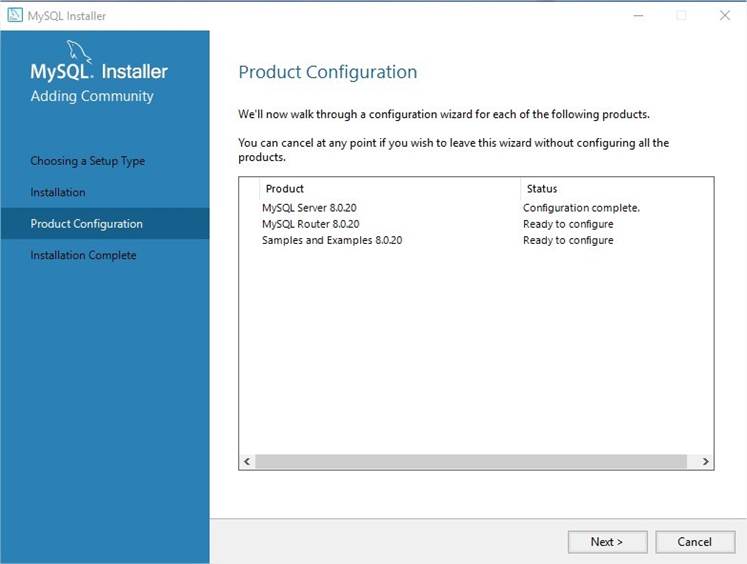
Etape07 : Configuratoin Rooter
Etape08 : Connecter au serveur (En utilisant le mot de passe confituré en étape 05.1)
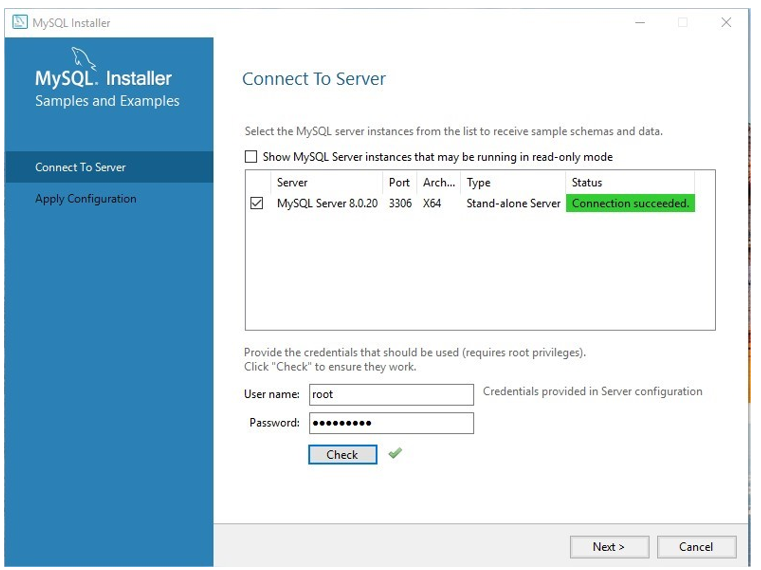
Etape09 : Appliquer les configurations
Etape10 : Installation terminée
5.2.3 Se connecter au serveur MySQL
Une fois le serveur MySQL installé, vous pouvez vous y connecter à l'aide de n'importe quel programme client tel que le client de ligne de commande mysql et le plan de travail MySQL.
5.2.3.1 Se connecter à MySQL à l'aide du client de ligne de commande mysql
MySQL est un programme client en ligne de commande qui vous permet d'interagir avec MySQL en mode interactif et non interactif.
Le client de ligne de commande mysql se trouve généralement dans le répertoire bin du dossier d'installation de MySQL.

Ouvrir l'invite de commande
Taper

Dans l'invite de commande
Pour appeler le programme mysql, il vous suffit de naviguer dans le répertoire bin du dossier d'installation de MySQL
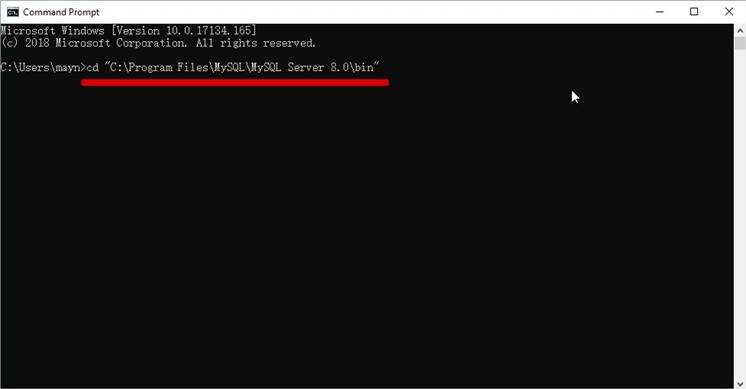
Et de taper:
Entrez le mot de passe que vous avez défini en étape 05.1 de section 5.2.2
Si tout va bien, vous vous connecterez au serveur MySQL avec la commande suivante:
Pour afficher les bases de données sur le serveur actuel, vous utilisez l'instruction SHOW DATABASES:

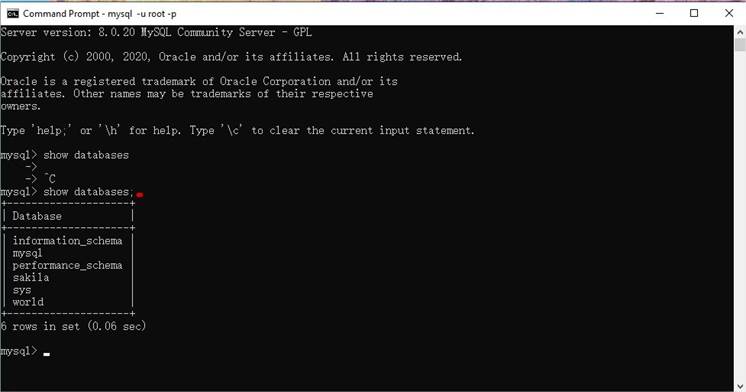
5.2.3.2 Se connecter à MySQL à l'aide de MySQL Workbench
Etape01 : Lancez MySQL Workbench

Vous pouvez vous connecter à un serveur MySQL à l'aide du menu Base de données> Se connecter à la base de données… ou cliquer sur le bouton + qui se trouve à côté des connexions MySQL.
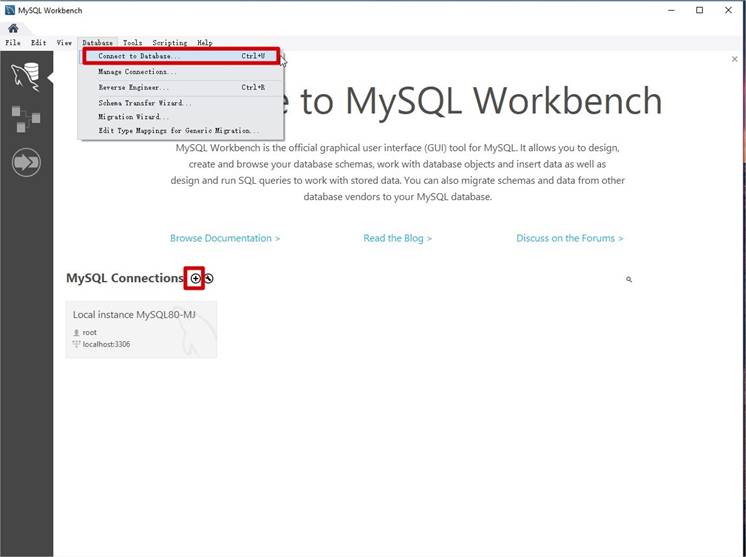
Cliquez simplement sur le bouton + à côté des connexions MySQL pour continuer.
Etape02 : Saisissez le nom de la connexion, par exemple Localhost. Vous pouvez le nommer comme vous voulez. Par défaut, le nom d'utilisateur est root. Si vous utilisez un autre compte utilisateur, vous pouvez le modifier dans la zone de texte Nom d'utilisateur.
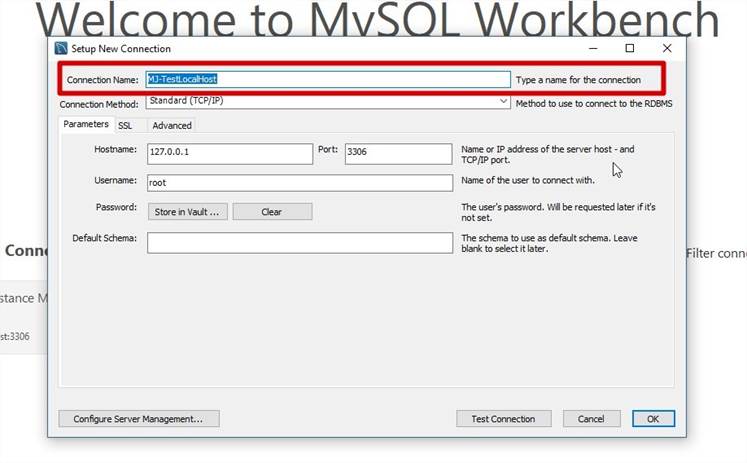
Etape03 : Cliquez sur le bouton Store in Vault ... pour entrer le mot de passe du compte d'utilisateur fourni. Une fenêtre s'affiche. Vous entrez le mot de passe et cliquez sur le bouton OK.
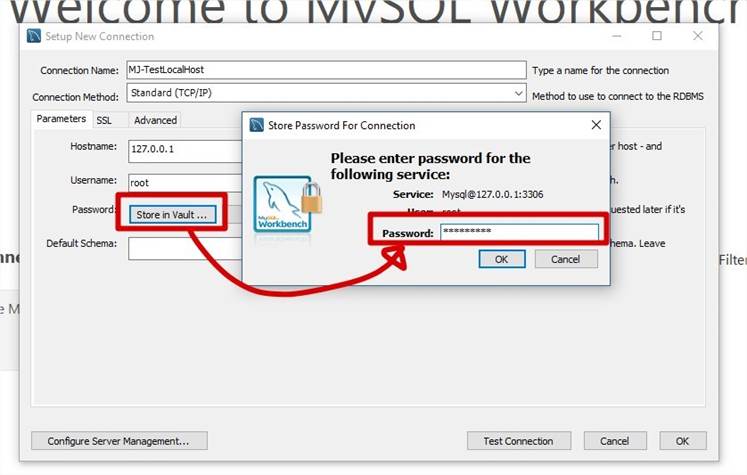
Etape04 : Cliquez sur le bouton Tester la connexion pour tester si la connexion au serveur MySQL a réussi ou non. Cliquez ensuite sur le bouton OK si la connexion est établie avec succès.
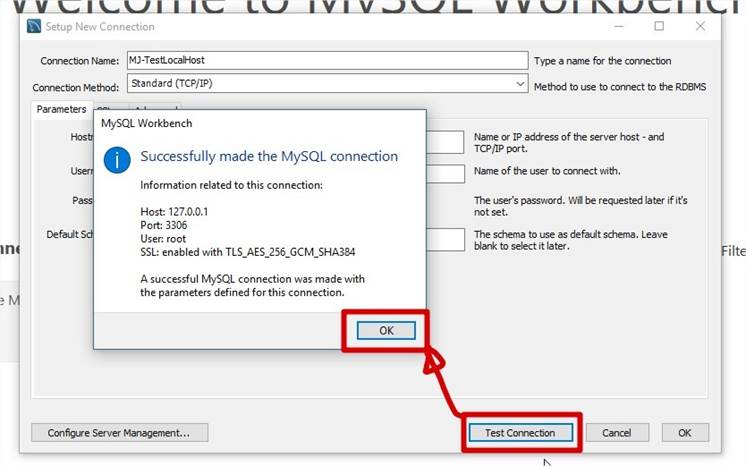
Etape05 : Cliquez sur le bouton OK pour enregistrer la connexion.
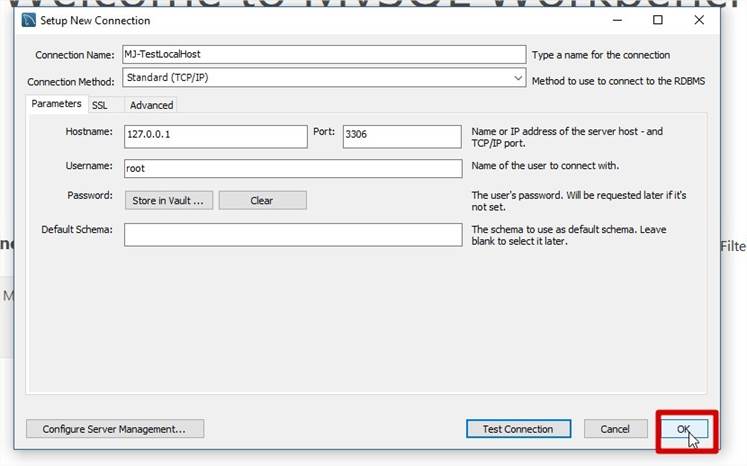
Etape05 : Cliquez sur la connexion nouvellement créée sous Connexions MySQL pour vous connecter au serveur MySQL:
Etape 07 : Affichage de MySQL Workbench avec les schémas actuels et un volet pour entrer des requêtes:
5.2.4 Exemple de base de données MySQL
Nous utilisons la base de données classicmodels comme exemple de base de données MySQL pour vous aider à travailler avec MySQL rapidement et efficacement. La base de données classicmodels est un détaillant de modèles réduits de base de données de voitures classiques. Il contient des données commerciales typiques telles que les clients, les produits, les commandes client, les lignes de commande client, etc.
5.2.4.1 Télécharger la base de données exemple MySQL
Vous pouvez télécharger l'exemple de base de données MySQL via le lien suivant: https://www.mysqltutorial.org/wp-content/uploads/2018/03/mysqlsampledatabase.zip
![]()
Le fichier téléchargé est au format ZIP, vous avez donc besoin d'un programme zip pour le décompresser.
Vous pouvez télécharger un programme zip gratuit sur www.7-zip.org
![]()
5.2.4.2 Comment charger l'exemple de base de données dans le serveur MySQL
Etape 01 : Décompressez le fichier téléchargé (mysqlsampledatabase ) dans un dossier temporaire. Vous pouvez utiliser n'importe quel dossier de votre choix. Pour simplifier, nous allons décompresser le fichier dans le dossier:
Etape 02 : Connectez-vous au serveur MySQL

Etape 03 : Utilisez la commande source pour charger des données dans le serveur MySQL
![]()

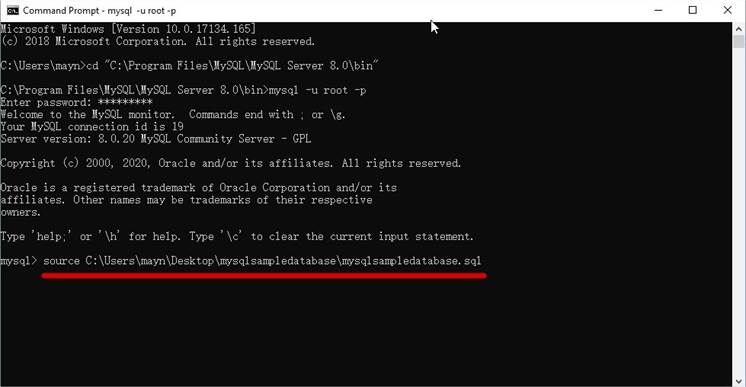
Etape 04 : Utilisez la commande SHOW DATABASES pour répertorier toutes les bases de données du serveur actuel
6.Mongo overview
Comme tout autre langage de gestion de base de données, MongoDB est basé sur une base de données NoSQL qui est utilisée pour stocker des données dans une paire clé-valeur. Son fonctionnement est basé sur le concept de document et de collection. Il s'agit également d'un système de base de données multiplateforme open-source, orienté document qui est écrit en C ++. Dans ce chapitre, vous en apprendrez plus sur MongoDB et son importance.
Mongo DB peut être défini comme un système de base de données orienté document qui utilise le concept de NoSQL. Il offre également une haute disponibilité, des performances élevées et une mise à l'échelle automatique. Ce produit open-source a été développé par la société - 10gen en octobre 2007, et la société le maintient également. MongoDB existe sous la licence publique générale (GPL) en tant qu'outil de gestion de base de données gratuit et disponible sous licence commerciale du fabricant. MongoDB était également destiné à fonctionner avec des serveurs de base. Des entreprises de tailles différentes dans le monde entier dans toutes les industries utilisent MongoDB comme base de données.
Voici quelques terminologies clés que vous devez connaître pour approfondir MongoDB:
Qu'est-ce qu'une base de données ?
Dans MongoDB, une base de données peut être définie comme un conteneur physique pour les collections de données. Ici, sur le système de fichiers, chaque base de données a sa collection de fichiers résidant.
Habituellement, un serveur MongoDB contient de nombreuses bases de données.
Quelles sont les collections?
Les collections peuvent être définies comme un cluster de documents MongoDB qui existent dans une seule base de données. Vous pouvez associer cela à celui d'une table dans un système de gestion de base de données relationnelle. Les collections MongoDB n'implémentent pas le concept de schéma. Les documents qui ont une collection contiennent généralement différents champs. En règle générale, tous les documents résidant dans une collection sont destinés à un usage comparable ou connexe.
Qu'est-ce qu'un document
Un document peut être défini comme une collection de paires clé-valeur qui contiennent un schéma dynamique. Le schéma dynamique est quelque chose que les documents de la même collection ne nécessitent pas pour avoir la même collection de champs ou de construction, et un champ commun est capable de contenir différents types de données.
Pourquoi utiliser MongoDB?
Les débutants doivent connaître le but et l'exigence de pourquoi utiliser MongoDB ou quel est son besoin contrairement à SQL et à d'autres systèmes de base de données. En termes simples, on peut dire que chaque application moderne implique le concept de Big Data, l'analyse de différentes formes de données, l'amélioration rapide des fonctionnalités dans la gestion des données, la flexibilité de déploiement, que les anciens systèmes de base de données ne sont pas suffisamment compétents pour gérer. Par conséquent, MongoDB est le choix suivant.
Voici une liste de quelques sociétés et organisations populaires et multinationales qui utilisent MongoDB comme base de données officielle pour exécuter et gérer différentes applications commerciales.
Adobe, McAfee, LinkedIn, FourSquare, MetLife, eBay, Google etc.

6.1 Guide d'installation du Mongo DB:
1. aller sur le site
https://www.mongodb.com/try/download/community
![]()
choisissez les paramètres suivants et cliquez sur download

https://www.mongodb.com/try/download/shel
https://www.mongodb.com/try/download/compas
2. ouvrez le ficher téléchargé et cliquez sur Next.
le nom du fichier est par exemple mongodb-win32-x86_64-2012plus-4.2.6-signed.msi", il varie selon les paramètres choisis.
3. Cochez "I accept the terms...." puis Cliquez sur next
4. Choisissez "Complete" et puis Next
Il est fortement conseillé de garder ces paramètres par défaut. Si vous voulez les modifiez, gardez vos paramètres personnalisés quelques parts.
5.Allez jusqu'au bout, un redémarrage est attendu à la fin de l'installation

6.2 Vérification
Après le redémarrage, vérifions d'abord les choses suivantes :
1. le service Mongo est bien démarré
Si c'est le cas, le coeur du Mongo (Mongo server) est bien installé et bien démarré.
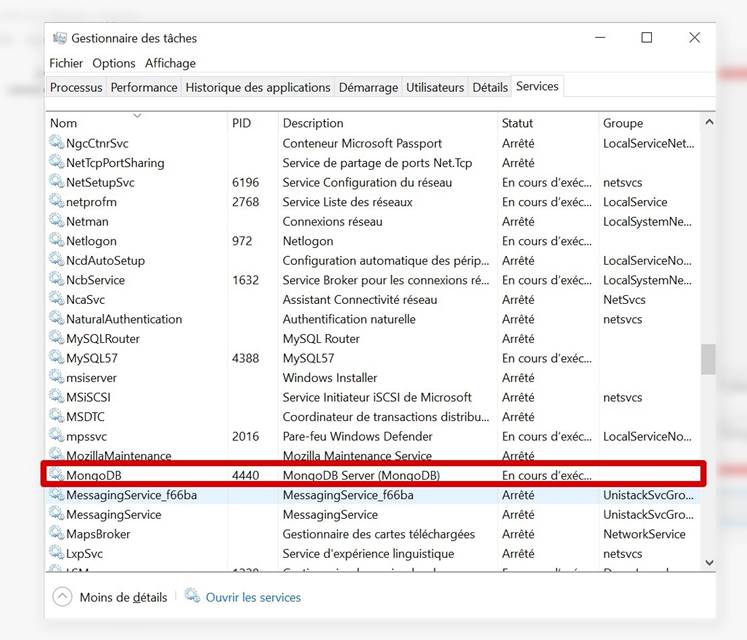
2. Exécuter mongo dans un environnement de shell.

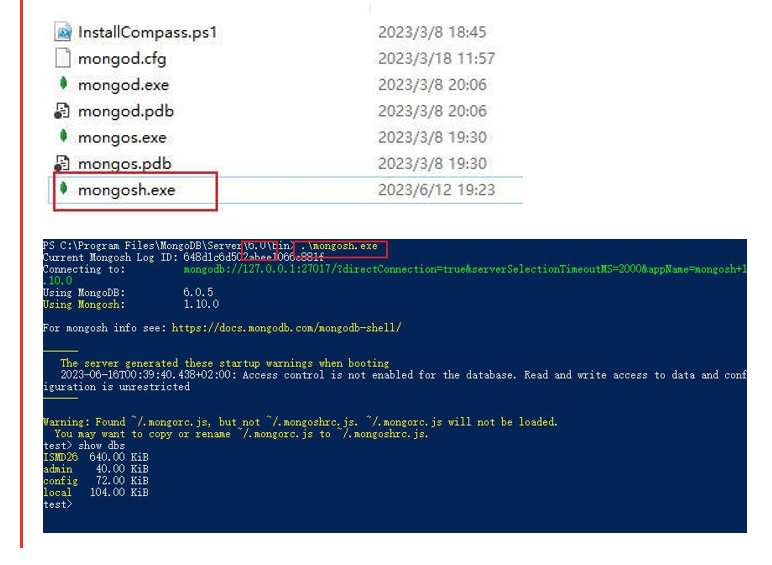
![]()
1. Ouvrez un terminal de windows en tapant "cmd" dans la barre de recherche de windows
2. tapez "cd C:\Program Files\MongoDB\Server\4.2\bin", le home directory de votre installation
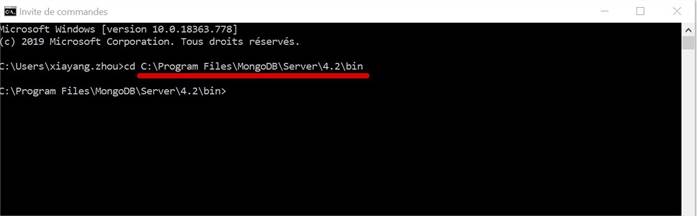
3. tapez ensuite mongo puis enter
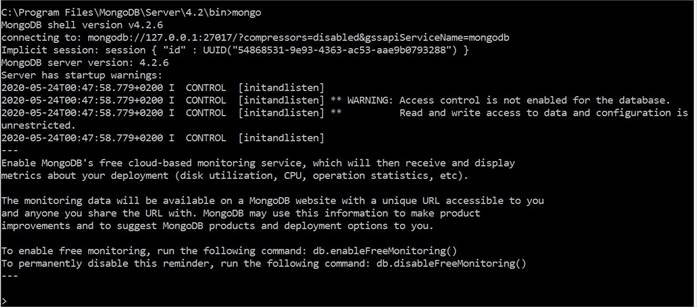
Si vous avez un message similaire au celui du ci-dessus, vous avez donc réussi à le démarrer.
Nous allons faire une dernière configuration avant de l'utiliser
Nous pouvons donc dès maintenant exécuter mongo à partir de n'importe quel directory.
6.3 Utilisation


Tapez "show dbs" (show databases), puis "enter", vous verrez une liste de databases qui sont déjà créées par défaut.
Passons maintenant au client du Mongo pour pouvoir manipuler avec une interface graphique. Ouvrez
"MongoDB Compass" et vous allez voir l'interface suivante
et appuyez sur Connect. Si vous avez un autre serveur Mongo, sur lequel vous pouvez vous connecter à travers un string de url, user et mot de passe. Nous sommes ici en mode locolhost sans mdp, vous pouvez donc vous connecter directement sur le serveur tourné sur votre propre machine.
Nous pouvons voir les trois mêmes databases que nous avons vues précédemment dans un terminal. Ajouter une database "Test1" avec une collection products
vous pouvez voir de la même façon dans le terminal que nous avons maintenant 4 databases, y compris
Test1
6.4 Insert
Insérons un premier document dans Test1, soit dans le client de Mongo soit par une ligne de commande dans un terminal
Vous pouvez saisir votre document sous format de json ou key-value
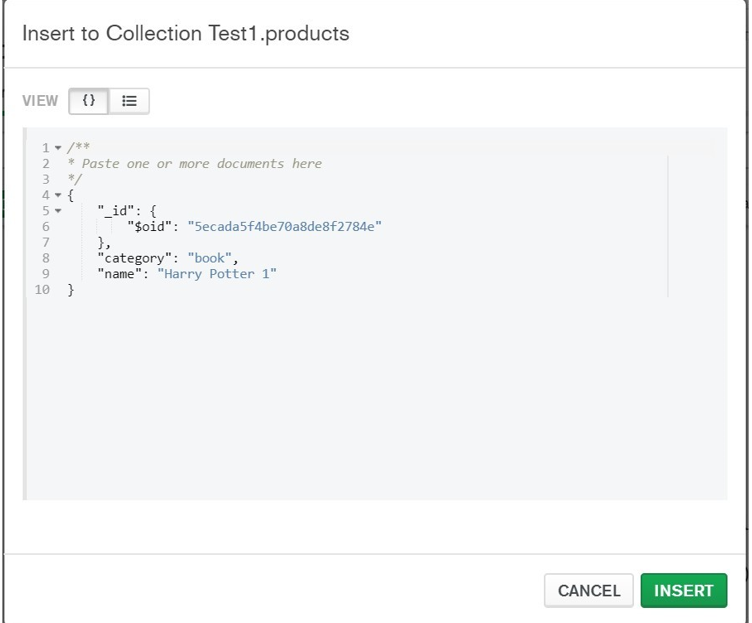
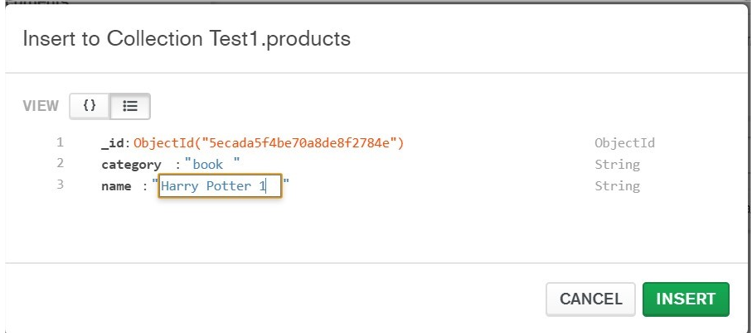
Dans un terminal:
tapez dans l'ordre les commandes suivantes

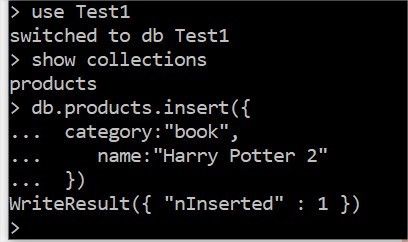
![]() Remarque: les attributs (ex: category et name) sont souvent entourées de guillemets. car ce sont des conventions de javascript et json. on a en expliquer plus dans les prochains chapitres. Mais Mongo sait lire sans guillemets, on omet parfois ces guillemets pour simplifier les requêtes qui sont considérer comme une chaine de caractères au lieu d'un fichier json . En revanche, si on prépare un document ou une requête via "import", il est obligatoire d'en ajouter, même des fois ça peut passer.
Remarque: les attributs (ex: category et name) sont souvent entourées de guillemets. car ce sont des conventions de javascript et json. on a en expliquer plus dans les prochains chapitres. Mais Mongo sait lire sans guillemets, on omet parfois ces guillemets pour simplifier les requêtes qui sont considérer comme une chaine de caractères au lieu d'un fichier json . En revanche, si on prépare un document ou une requête via "import", il est obligatoire d'en ajouter, même des fois ça peut passer.
Nous avons ainsi réussi à insérer deux documents dans la collection product de la base Test1
6.5 Read
Essayons maintenant d'utiliser la méthode find() d'une collection qui permets de lire et afficher les documents dans une collection donnée.
Syntaxe:
![]() db.collection_name.find(query** ,** projection ) query = condition de
db.collection_name.find(query** ,** projection ) query = condition de
- filtrage, OPTIONEL et du type document
- Projection = les champs à afficher dans le résultat retourné, OPTIONEL et du type document.
- Exemple: (à essayer dans le terminal)
 db.products.find()
db.products.find()
Afficher tous les documents dans la courante collection
![]() db.products.find().pretty()
db.products.find().pretty()
Afficher tous les documents avec un format plus lisible en séparant les champs ![]() db.products.find({category:"book"})
db.products.find({category:"book"})
Afficher tous les documents ayant une propriété "category" égale à "book"
* query = {category:"book"}, projection = vide dans cet exemple ![]() db.products.find({category:{$ne:"book"}})
db.products.find({category:{$ne:"book"}})
![]() Afficher tous les documents ayant une propriété "category" différent de "book"
Afficher tous les documents ayant une propriété "category" différent de "book"
- query = {category:{$ne:"book"}} projection = vide

- db.products.find({}, {name:true})
![]() Afficher le "name" de tous les documents
Afficher le "name" de tous les documents
- query = vide projection = {name:true}

- db.products.find({category:{$ne:"book"}})
Afficher tous les documents ayant une propriété "category" = "book" et une quantité "qty" = 10.
 query = {category:"book", qty: 10}, il y a donc bien deux conditions composées projection
query = {category:"book", qty: 10}, il y a donc bien deux conditions composées projection- = vide
6.6 Supression d'une collection et d'une database
Pour supprimer une collection dans MongoDB, vous devez utiliser la méthode collection.drop (). Cela éliminera complètement la collection de la base de données et ne laissera aucun index connecté à cette collection de dépôt. Il est également à noter que cette méthode de suppression de collection ne contient aucun argument et apparaîtra avec des erreurs au cas où des arguments seraient transmis. Tous les index associés à la collection sont supprimés une fois cette méthode exécutée.
La syntaxe pour utiliser cette méthode est:

Voici un exemple qui montre l'utilisation de la méthode drop ():
En reprenant l'exemple précédent où vous avez créé une collection dans la base de données Test1. Utilisez maintenant cette base de données pour supprimer la collection de products et voir les modifications:

Voici un exemple de output dans un terminal:
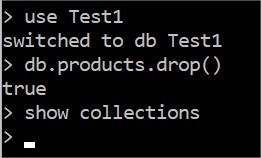
Modifié le: dimanche 30 mars 2025, 08:46
 E-BLEARN
E-BLEARN