 E-BLEARN
E-BLEARN
Page
Chapitre 1 - Mathématiques & Python
Conditions d’achèvement
![]()
![]()
Python
Module 01
Prérequis
Mathématiques & Python
Introduction Générale
Data, Qu'est ce que c'est?
Analyse de données, qu'est ce que c'est?
Impact d'analyse de données sur les entreprises
Défis et opportunités
Le cadre de données et d'analyse
Les 4 aspects du cadre de données et d'analyse
Cadre de données et d'analyse: outils et techniques
Techniques et outils d'analyse des données
Explorer les outils d'analyse de données
SQL
Python
R, Qu'est-ce que le CRAN?
Explorer les outils de visualisation Le pouvoir de la visualisation
Tableau (et Tableau Public)
Datawrapper
D3.js
Google Charts
Prérequis Python
Langages
Langage humain
Langage machine
Langages de programmation
Bref histoire du Python
Pourquoi Python pour ce programme Data?
Un langage de programmation interprété
Installer Python avec Anaconda
Téléchargez et installez Anaconda
Ajouter Anaconda au chemin (facultatif)
Prérequis Python - Jupyter Notebook Introduction à Jupyter Notebook
Notions de base sur Jupyter Notebook
Jupyter Notebook Dashboard
Présentation de l'interface utilisateur (UI) du notebook
Mode édition
Mode commande
Navigation avec la souris
Navigation avec le clavier
Premiers tests
Texte "Hello world"
Calculs natifs
Saisir un nombre
Opérations
Addition, soustraction, multiplication, division
Division entière et modulo
Prérequis Python - Programmation
Variables
Définition d'une variable
Opérations sur une variable
Types de données
Déclaration du type de données
Introduction aux différents types de données
Python - Nombres entiers
Python - Nombres flottants
Python - Chaînes de caractères
La fonction len () renvoie la longueur d'une chaîne:
La méthode strip () supprime tout espace du début ou de la fin:
La méthode lower () renvoie la chaîne en minuscules:
La méthode upper () renvoie la chaîne en majuscules:
La méthode replace () remplace une chaîne par une autre chaîne:
La méthode split () divise la chaîne en sous-chaînes si elle trouve des instances du séparateur:
Pour vérifier si une certaine phrase ou un certain caractère est présent dans une chaîne, nous pouvons utiliser les mots clés in ou not in .
f-Strings: une façon nouvelle et améliorée de formater les chaînes en Python
Python - Listes
Pour déterminer le nombre d'éléments d'une liste, utilisez la fonction len () :
Ajouter de nouveaux éléments à la fin de la liste, en utilisant la méthode append () :
Pour ajouter un élément à l'index spécifié, utilisez la méthode insert () :
La méthode remove () supprime l'élément spécifié:
La méthode pop () supprime l'index spécifié, (ou le dernier élément si l'index n'est pas spécifié):
Le mot clé del supprime l'index spécifié:
Faites une copie d'une liste avec la méthode copy () :
Rejoignez deux listes
Structures conditionnelles
Déclaration if
Déclaration else Déclaration elif
Opérateurs de comparaison
Mots-clés and , or et not
Boucles
Python - Boucle for - for Loop
Python - Fonction range ()
Python - Boucle while - while Loop
Exercice 4.4.3 - 1 : Comment pouvons nous réécrire le programme de la section 4.4.2 avec la boucle while ?
Exercice 4.4.3 - 2 : Quelle est la somme de tous les nombres entiers entre 1 et 100(Avec les deux bords inclus)? Utilisons la boucle while
Prérequis Python - Fonctions & Classes
Fonctions
Mot-clé def
Table de multiplication par 9
Exercice 5.1.2 - 1 Instruction Return
Premier programme
Fonction input()
Un simple programme pour déterminer si une année est bissextile
Un peu de simplification
Gérez les exceptions
Try - Except
Déclaration finally
Déclaration pass
Les assertions - assert
Conception de classe
Syntaxe de définition de classe
Objets de classe
Un exemple simpliste - Matrices help() __repr__()
L'attribut spécial __dict__
Les propriétés
Implémentation 01 - Simple
Implémentation 02 - Interface getter/setter
Implémentation 03 - Implémentation pythonique
Implémentation de Temperature
Les Méthodes spéciales
Édition de l'objet
__init__
__del__
Accès aux attributs de notre objet
__getattr__
__setattr__
La méthode spéciale derrière le mot-clé in
D'autres opérateurs
__iadd__
Importer votre propre module
Etape 01 - Nouveau Notebook
Etape 02 - Créer votre classe de test et télécharger le fichier en .py
Importer votre propre module
Importer des objets individuels
Prérequis Mathématiques
Probabilité & Statistique
Algèbre linéaire
Prérequis Mathématiques - Analyse combinatoire
Arrangements avec répétitions
Arrangements sans répétition
Combinaisons sans remise
Propriétés des combinaisons
Formule du binôme de Newton
Prérequis Mathématiques - Probabilité
Espace fondamental et évènements Définition de l'espace probabilisable Opération ensembliste: L'intersection de deux évènements
La réunion de deux évènements
Le complémentaire d'un événement
L’inclusion d’un évènement
Probabilité
Probabilité conditionnelle
Indépendance entre deux événements
Indépendance entre plusieurs événements
Prérequis Mathématiques - Variables aléatoires
Variables aléatoires
Fonction de répartition
Espérance mathématique
Variables aléatoires discrètes
Variables aléatoires continues Propriété de la moyenne:
Variance et Ecart-type
La variance d'une Variable aléatoire discrète
La variance d'une Variable aléatoire continue
Propriétés de la variance
Prérequis Mathématiques - Couples de variables aléatoires discrètes
Loi conjointe
Lois marginales
Indépendance de variables aléatoires discrètes
Espérance, matrice de covariance
Prérequis Mathématiques - Statistique descriptive
Liens avec les concepts probabilistes
Moyenne empirique
Médiane empirique Variance empirique
Ecart-type empirique
Prérequis Mathématiques - Estimation
Convergence
Biais d’un estimateur
L'erreur quadratique ou le risque quadratique
. Exemples fondamentaux
Estimation de m
![]() Estimation de en supposant m connu
Estimation de en supposant m connu
Estimation de lorsque m est inconnu
Prérequis Mathématiques - Algèbre linéaire
Espace Vectoriel
Sous espace Vectoriel
Combinaison linéaire
Définition
Vecteurs engendrés, familles génératrices
Familles libres ou liées
Bases, et par là dimension d’un espace vectoriel, coordonnées
Calcul Vectoriel
Norme euclidienne
Produit scalaire
Définition géométrique du produit scalaire Définition mathématiques (hors programme):
Quelques propriétés:
Distance sur des espaces vectoriels
Application linéaire
Définition
Matrice
Application linéaire et Matrice
 1 Introduction Générale
1 Introduction Générale
1.1 Data, Qu'est ce que c'est?
Webster définit les données comme un ensemble de faits, d'observations ou d'autres informations liées à une question ou un problème particulier. Les données peuvent être structurées ou non structurées.
Les données structurées sont des informations qui présentent un haut degré d'organisation, qui pourraient être incluses dans des bases de données ou des feuilles de calcul et qui sont facilement consultables par de simples algorithmes de moteur de recherche. Comprendre les données structurées est plus facile avec un exemple des cotations boursières :
 Les données non structurées sont l'opposé, elles sont généralement riches en texte, bien qu'elles puissent également contenir des vidéos, des données numériques ou des faits. Pensez à une zone de texte de champ ouvert qui vous permet de fournir des commentaires supplémentaires sur une enquête.
Les données non structurées sont l'opposé, elles sont généralement riches en texte, bien qu'elles puissent également contenir des vidéos, des données numériques ou des faits. Pensez à une zone de texte de champ ouvert qui vous permet de fournir des commentaires supplémentaires sur une enquête.
Voici un exemple :
![]() Un fichier d'image peut être considéré comme une donnée non structurée. Les données sous forme vidéo
Un fichier d'image peut être considéré comme une donnée non structurée. Les données sous forme vidéo
peuvent également être considérées comme non structurées.
L'ajout de la complexité réside dans le fait que les données peuvent également provenir de diverses sources internes et externes pour les organisations. La conversation devient vraiment intéressante lorsque nous examinons la grande variété de données dont nous disposons aujourd'hui et les analyses puissantes qui peuvent être appliquées à ces données.
1.2 Analyse de données, qu'est ce que c'est?
L'analyse des données est la science qui consiste à examiner des données brutes afin de tirer des conclusions à partir des informations qu'elles contiennent. C'est un domaine passionnant qui a un impact considérable sur la manière dont les organisations de nombreuses industries prennent leurs décisions.
La disponibilité d'énormes volumes de données structurées et non structurées, combinée à des capacités informatiques avancées, à un stockage à faible coût et à une technologie de visualisation puissante, permet aux organisations d'obtenir des informations qui étaient auparavant technologiquement impossibles à acquérir ou économiquement irréalisables. Cela permet également à de nouvelles entités de démarrer et de se développer rapidement, ce qui peut apporter de grands avantages au marché et à la société, mais peut également être très perturbateur et remettre en question le statu quo. D'où proviennent donc ces données ? Elles viennent d'études de marché, de médias sociaux et du réseau d'objets physiques que nous appelons l'Internet des Objets. Le monde dans lequel nous vivons aujourd'hui crée un flux constant et toujours croissant de données. Pour la plupart des organisations, les données auxquelles elles peuvent accéder augmentent à un taux de 40% chaque année, ce qui crée d'importants défis en matière de capture et de sécurisation des données, d'organisation, d'analyse et de rapport.
1.3 Impact d'analyse de données sur les entreprises
Tout d'abord, les données permettent la création de nouveaux produits et services, générant des marchés qui n'existaient pas auparavant et apportant de nouvelles capacités aux marchés existants.
![]() Les appareils portables, tels que le Fitbit ou l'Apple Watch, sont des exemples de ces nouveaux produits.
Les appareils portables, tels que le Fitbit ou l'Apple Watch, sont des exemples de ces nouveaux produits.
Deuxièmement, les données peuvent perturber les marchés existants, avec l'apparition de nouveaux acteurs qui bouleversent les entreprises traditionnellement établies.
![]() Uber, par exemple, a révolutionné le marché des taxis.
Uber, par exemple, a révolutionné le marché des taxis.
Troisièmement, les données et les analyses améliorent l'efficacité.
![]() Les détaillants, par exemple, ont désormais la possibilité d'automatiser et d'optimiser leur chaîne d'approvisionnement. Ils peuvent adapter leurs offres pour les clients, rendant des services tels que la livraison le
Les détaillants, par exemple, ont désormais la possibilité d'automatiser et d'optimiser leur chaîne d'approvisionnement. Ils peuvent adapter leurs offres pour les clients, rendant des services tels que la livraison le
jour même d'Amazon dans les grandes villes américaines logistiquement possibles.
En résumé, les données permettent aux organisations d'identifier des opportunités de croissance, de stimuler l'innovation, d'opérer plus efficacement et de gérer les risques de nouvelles manières.
1.4 Défis et opportunités
Si les données peuvent faire tout cela, il semble évident que les organisations devraient simplement les exploiter pour rester compétitives. Mais comment le faire ? Les organisations ont toujours utilisé des données, sous une forme ou une autre, pour éclairer leurs décisions.
Cependant, le volume, la variété et la vitesse des données disponibles aujourd'hui posent d'énormes défis. Les approches traditionnelles de l'analyse des données, qui consistent à identifier un problème ou une opportunité commerciale, à collecter des données et à utiliser des feuilles de calcul ou des logiciels pour les comprendre, ne sont plus suffisantes. Aujourd'hui, le volume d'informations est tout simplement trop élevé et le délai trop court. Pourtant, relever ces défis peut conduire à d'immenses récompenses. Les organisations avisées exploitent l'analyse des données pour obtenir une image plus claire de leur activité. Elles utilisent de nouvelles technologies, comme la visualisation des données. Présenter les données sous une forme picturale ou graphique aide les décideurs à visualiser les analyses et à identifier plus facilement de nouveaux modèles. Ce type de perspective est puissant et peut fondamentalement changer la vitesse et la sophistication de la prise de décision.
1.5 Le cadre de données et d'analyse
Dans cette section, nous allons explorer le cadre de l'analyse de données. Nous discuterons des éléments constitutifs de ce cadre et expliquerons pourquoi il est important de suivre une structure lors de la résolution d'un problème commercial.
![]() “
“
Exemple 1.5 :
![]() Une compagnie d'assurance internationale est venue à nous avec le souhait d'intégrer des données et des analyses avancées dans son organisation. Elle avait plusieurs objectifs commerciaux à atteindre, dont l'amélioration de la rétention et des ventes croisées dans un pays, et l'augmentation des acquisitions dans un autre. Elle voulait construire une organisation axée sur l'analyse, tout en veillant à résoudre un problème commercial spécifique. Nous avons utilisé notre cadre de données et d'analyse pour déterminer d'abord les résultats souhaités dans chaque pays. Par exemple, comme mentionné, augmenter la rétention de produits croisés dans un pays. Ensuite, nous avons listé toutes les actions ou décisions qu'ils pourraient prendre pour obtenir ce résultat. Par exemple, déterminer qui cibler, quand, pourquoi et par quel canal.
Une compagnie d'assurance internationale est venue à nous avec le souhait d'intégrer des données et des analyses avancées dans son organisation. Elle avait plusieurs objectifs commerciaux à atteindre, dont l'amélioration de la rétention et des ventes croisées dans un pays, et l'augmentation des acquisitions dans un autre. Elle voulait construire une organisation axée sur l'analyse, tout en veillant à résoudre un problème commercial spécifique. Nous avons utilisé notre cadre de données et d'analyse pour déterminer d'abord les résultats souhaités dans chaque pays. Par exemple, comme mentionné, augmenter la rétention de produits croisés dans un pays. Ensuite, nous avons listé toutes les actions ou décisions qu'ils pourraient prendre pour obtenir ce résultat. Par exemple, déterminer qui cibler, quand, pourquoi et par quel canal.
1.5.1 Les 4 aspects du cadre de données et d'analyse
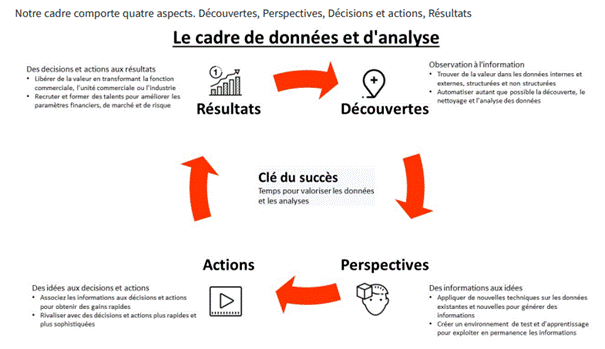
Sortons de la vision globale pour revenir en arrière et définir le problème ainsi que l'analyse à effectuer. À chacune des quatre étapes, nous prenons des mesures pour garantir le temps nécessaire pour valoriser l'analyse des données. Durant la phase de découverte, vous devez définir le problème, développer une hypothèse et collecter et explorer des données. Pendant la phase d'analyse, vous effectuez l'analyse des données. Ensuite viennent les actions où vous transformez les informations en recommandations exploitables et en un plan d'exécution. Enfin, vous passez en revue les résultats qui ont transformé l'entreprise, l'unité commerciale ou l'industrie. Nous partons des résultats commerciaux pour définir le problème que nous essayons de résoudre. Nous examinons souvent les questions auxquelles il faut répondre ou les problèmes clés qui doivent être résolus, ainsi que les métriques qui doivent être prises en compte. Cela nous permet non seulement de définir le problème, mais aussi de formuler notre hypothèse sur la façon dont nous allons influencer les résultats. Une fois que nous avons déterminé les résultats à atteindre, nous examinons les décisions que les dirigeants doivent prendre ou les actions que les employés doivent entreprendre. Cela nous permet d'identifier les variables dépendantes critiques, les décisions ou les actions, ou l'output requis pour prendre les bonnes décisions et actions. En fonction de la complexité du problème et du temps disponible, nous examinons différentes techniques qui peuvent être utilisées pour générer ces informations. Cela commence généralement par comprendre ce qui s'est passé jusqu'à présent, ce que l'organisation a fait et comment elle peut le faire à l'avenir, afin que nous puissions influencer les décisions et les actions clés. Une fois que nous avons identifié les techniques qui généreront les informations, nous pouvons rechercher les bonnes données disponibles. Les données peuvent être internes ou externes à l'organisation. Elles peuvent également être structurées ou non structurées. La nature des données disponibles, le temps disponible pour les obtenir, mais influencent les techniques que nous pourrions potentiellement utiliser pour générer des informations. C'est un processus itératif. Il est toujours préférable de partir des résultats et de l'hypothèse plutôt que des données disponibles pour générer la meilleure valeur à partir des données et des analyses.
Récapitulons donc le cadre d'analyse des données. Durant la phase de découverte, vous définissez le problème, développez une hypothèse et collectez et explorez les données. Pendant la phase d'analyse, vous effectuez l'analyse des données. Le volet actions est celui où vous transformez les informations en recommandations exploitables et en un plan d'exécution. Enfin, vous passez en revue les résultats des objectifs et des solutions à long terme.
Ce cadre nous permet de naviguer l'analyse des données de manière organisée et nous fournit le processus à suivre lorsque nous travaillons avec les clients pour résoudre un problème. Dans la section suivante, je vais parler des types d'analyses que vous pouvez effectuer et vous montrer les outils que vous pouvez utiliser dans le cadre d'analyse de données.
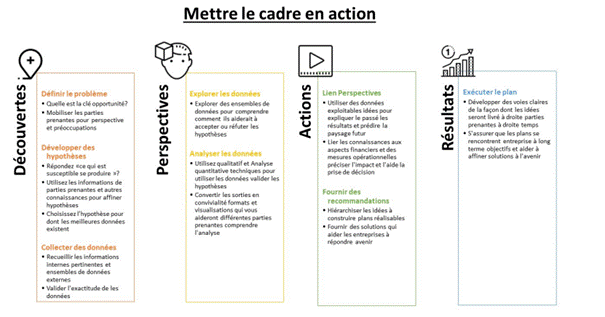
1.5.2 Cadre de données et d'analyse: outils et techniques
Maintenant que nous avons introduit les données et le cadre analytique, nous devons répondre à la question : quelles techniques analytiques puis-je utiliser et quels outils peuvent m'aider ? Dans cette sous-section, nous allons parler de cinq types d'analyses de données et des outils utilisés pour construire notre analyse. Nous classons les types d'analyses que l'on peut effectuer en cinq catégories :
![]() Analyse descriptive
Analyse descriptive
Analyse diagnostique
Analyse prédictive
Analyse prescriptive
Analyse adaptative et autonome
![]() Ce sont les grandes catégories qui vous aideront à utiliser le cadre de données et d'analyse dont nous avons discuté dans la section 1.5.1 . Le cadre est abstrait, mais ces types d'analyses vous aideront à le rendre opérationnel.
Ce sont les grandes catégories qui vous aideront à utiliser le cadre de données et d'analyse dont nous avons discuté dans la section 1.5.1 . Le cadre est abstrait, mais ces types d'analyses vous aideront à le rendre opérationnel.
Comme nous l'avons vu précédemment, l'une des utilisations courantes de l'analyse en marketing est la vente croisée de plusieurs produits aux clients. Lorsque nous avons examiné les résultats de l'augmentation du nombre de produits croisés de nos clients, nous avons commencé par l'analyse descriptive. Nous avons examiné leurs données pour profiler leurs clients en fonction du nombre de produits détenus : un produit, deux produits, etc. Ces profils comprenaient les données sociodémographiques du client, leurs comportements en ligne et hors ligne, leurs attitudes, le moment de la vie où ils ont acheté ces produits, etc.
L'analyse descriptive vous aide à comprendre l'état actuel des choses dans une organisation. Elle vous permet d'observer ce qui se passe aujourd'hui et ce qui s'est passé dans le passé. Ce type d'analyse fournit généralement des informations résumées pour comprendre les modèles de vente ou le comportement du client, la rentabilité du client, les actions passées des concurrents, etc. Les techniques spécifiques peuvent inclure de simples diagrammes en boîte, des histogrammes avec des moyennes, des minimums et des maximums. Tracer les données en quartiles ou déciles sur un certain nombre de variables différentes. Ou calculer des mesures statistiques comme la moyenne, le mode, l'écart-type, etc. L'analyse descriptive est très puissante pour comprendre l'état actuel des choses et pour développer l'hypothèse afin d'anticiper où se situent les problèmes et les opportunités d'affaires. Cela nous aide à répondre à la question, que s'est-il passé ? Par exemple, à partir de l'analyse descriptive, il est apparu clairement qu'une grande proportion des clients de la compagnie d'assurance dont nous avons parlé dans la section précédente, n'avaient qu'un seul produit, et un très petit nombre de clients avaient quatre produits ou plus.
Après avoir obtenu une bonne description de la détention de produits croisés par différents clients, nous avons commencé à nous demander pourquoi celle-ci était si faible. Il s'est avéré que la compagnie d'assurance utilisait plusieurs canaux pour vendre ses produits : des agents captifs, des agents indépendants et du personnel de télémarketing. Chacun de ces canaux vendait efficacement un type de produit spécifique, ce qui a entraîné un nombre équivalent de clients mono-produits pour les trois canaux. Étant donné l'expertise de ces chaînes, il y a eu très peu de ventes croisées. La détention de plusieurs produits était davantage le résultat de clients demandant des produits supplémentaires, plutôt qu'un processus de vente croisée délibéré.
L'analyse diagnostique vous aide à comprendre pourquoi cela s'est produit. Elle fournit des explications sur ce qui s'est passé dans le passé. Ce type d'analyse cherche généralement à approfondir une raison ou des hypothèses spécifiques basées sur l'analyse descriptive. Alors que l'analyse descriptive jette un large filet pour comprendre la portée des données, l'analyse diagnostique plonge plus profondément, explorant les causes des problèmes. Par exemple, nous pourrions envisager de créer une analyse de l'arbre de décision des portefeuilles de produits croisés pour révéler les types de clients qui ont acheté ces produits, les canaux qu'ils utilisent, les produits qu'ils ont achetés et quand ils les ont achetés. Une fois que nous avons su quels étaient les principaux problèmes dans un portefeuille de produits à faible coût, nous avons commencé à formuler des hypothèses sur ce que nous pouvions faire pour augmenter les ventes croisées de produits. Nous avons construit un modèle prédictif pour classer les clients en fonction de leur propension à acheter un deuxième, un troisième ou un quatrième produit spécifique. Ce modèle prédictif a été construit sur la base de la compréhension que nous avons acquise des deux étapes précédentes de l'analyse descriptive et diagnostique. Vient ensuite l'analyse prédictive. Contrairement à l'analyse descriptive ou diagnostique, l'analyse prédictive est plus prospective. L'analyse prédictive vous permet d'imaginer ce qui pourrait arriver à l'avenir. Ce type d'analyse peut aider le client à répondre à des questions telles que : que feront probablement mes clients à l'avenir ? Que sont susceptibles de faire mes concurrents ? À quoi ressemblera le marché ? Comment l'avenir affectera-t-il mon produit ou service ? L'analyse prédictive prédit généralement ce qui pourrait se produire sur la base des preuves que nous avons recueillies.
![]() Dans notre étude de cas sur l'assurance Exemple 1.5 , une fois notre modèle de propension construit, nous avons pu identifier certaines des cibles à fort potentiel pour la vente croisée et déterminer quel produit leur serait le mieux vendu. Compte tenu des différentes propensions à l'achat, nous avons calculé la meilleure offre suivante pour chaque client et comment le message de vente croisée devrait être personnalisé pour chaque client et chaque canal de distribution. L'analyse prescriptive va au-delà de la simple formulation de recommandations, elle met réellement en œuvre les actions ou prend les décisions qui conviennent à une situation particulière. Pour ce faire, elle examine ce qui s'est passé dans le passé, l'état actuel et toutes les possibilités futures. L'analyse prescriptive fournit des réponses à la question : quelles mesures ou interventions doivent être prises pour atteindre les résultats souhaités ? Souvent, l'intervention peut être une solution optimale compte tenu des circonstances. Ou la meilleure action possible compte tenu de l'incertitude de l'environnement et des informations limitées disponibles. Elle implique souvent l'analyse de scénarios et/ou la recherche de solutions optimales. L'analyse prescriptive est puissante pour comprendre les bonnes actions à entreprendre aujourd'hui pour répondre aux possibilités futures et mettre une organisation en meilleure position pour tirer parti des conditions futures. Bien que nous ayons créé une solution unique pour permettre au client d'augmenter la détention de produits croisés de ses clients, ce dont ils avaient réellement besoin était un système adaptatif et continu qui apprend des interventions comportementales et des actions prises par les clients pour modifier automatiquement les
Dans notre étude de cas sur l'assurance Exemple 1.5 , une fois notre modèle de propension construit, nous avons pu identifier certaines des cibles à fort potentiel pour la vente croisée et déterminer quel produit leur serait le mieux vendu. Compte tenu des différentes propensions à l'achat, nous avons calculé la meilleure offre suivante pour chaque client et comment le message de vente croisée devrait être personnalisé pour chaque client et chaque canal de distribution. L'analyse prescriptive va au-delà de la simple formulation de recommandations, elle met réellement en œuvre les actions ou prend les décisions qui conviennent à une situation particulière. Pour ce faire, elle examine ce qui s'est passé dans le passé, l'état actuel et toutes les possibilités futures. L'analyse prescriptive fournit des réponses à la question : quelles mesures ou interventions doivent être prises pour atteindre les résultats souhaités ? Souvent, l'intervention peut être une solution optimale compte tenu des circonstances. Ou la meilleure action possible compte tenu de l'incertitude de l'environnement et des informations limitées disponibles. Elle implique souvent l'analyse de scénarios et/ou la recherche de solutions optimales. L'analyse prescriptive est puissante pour comprendre les bonnes actions à entreprendre aujourd'hui pour répondre aux possibilités futures et mettre une organisation en meilleure position pour tirer parti des conditions futures. Bien que nous ayons créé une solution unique pour permettre au client d'augmenter la détention de produits croisés de ses clients, ce dont ils avaient réellement besoin était un système adaptatif et continu qui apprend des interventions comportementales et des actions prises par les clients pour modifier automatiquement les
recommandations et essayer de nouvelles mesures. Une telle plateforme d'insight permanente où le système construit un modèle du monde réel, prend des mesures, apprend de l'environnement et s'adapte en permanence est la solution adaptative et autonome ultime.
L'analyse adaptative et autonome en est encore à ses débuts, la plupart des systèmes actuels sont prédictifs ou prescriptifs. Très peu d'entre eux sont totalement adaptatifs ou autonomes. Cependant, il existe un certain nombre d'entreprises qui construisent des solutions analytiques plus adaptatives ou autonomes, où nous supprimons l'intervention humaine de la boucle. La conduite autonome est un excellent exemple de solution analytique adaptative ou autonome. L'analyse adaptative et autonome répond aux questions sur la manière dont le système s'adapte aux changements ? Comment exécuter des solutions analytiques en continu ? Comment apprendre et corriger en permanence son comportement pour optimiser ses performances ?
Nous ne voulons peut-être pas construire des systèmes adaptatifs et autonomes dans tous les cas. Il peut y avoir des situations où nous souhaiterons conserver le décideur humain. Mais il peut y avoir d'autres situations où la rapidité de prise de décision est telle que l'intervention d'un humain peut être contre-productive. Le trading algorithmique pourrait en être un exemple.
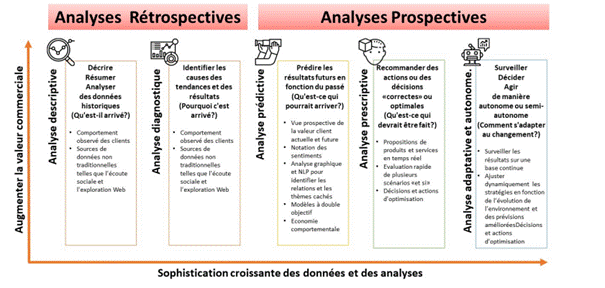
Maintenant que je vous ai donné un aperçu de haut niveau des différents types d'analyses, jetons un œil aux outils disponibles pour vous aider à les réaliser.
Les analyses descriptives et diagnostiques reposent généralement sur des outils analytiques capables de manipuler de grands ensembles de données ou qui facilitent la visualisation et l'interaction avec des informations résumées.
Voici quelques exemples de ces outils :
![]() SQL
SQL
Base de données Oracle
Hadoop / Spark
Tableau
QlikView
Microsoft Access
SAS
R
Python
Divers packages statistiques intégrés.
Les analyses prédictives et prescriptives s'appuient traditionnellement sur des outils d'analyse dotés de capacités de modélisation mathématique significatives ou de capacités de planification ou de simulation de scénarios.
Voici quelques exemples de ces outils :
![]() SAS
SAS
R
SPSS
Python
Outils d'optimisation comme Gurobi, ILOG, RiverLogic, etc.
Outils de simulation comme Vensim, AnyLogic, STELLA.
Outils de machine learning et de deep learning, tels que Scikit-learn, TensorFlow, Caffe, Theano, etc.
Outils de traitement du langage naturel, tels que NLTK (Natural Language Toolkit) ou OpenNLP.
Dans cette section, nous avons discuté de cinq types d'analyses différents que vous pouvez utiliser pour analyser des données. L'analyse descriptive vous aide à comprendre l'état actuel d'une situation et à répondre à la question : que s'estil passé ? L'analyse diagnostique vous aide à comprendre pourquoi cela s'est produit ou quelles sont les causes sousjacentes des données observées. L'analyse prédictive vous aide à comprendre ce qui pourrait arriver à l'avenir dans certaines conditions. L'analyse prescriptive vous aide à déterminer les meilleures actions à entreprendre aujourd'hui pour anticiper les défis futurs. Enfin, l'analyse adaptative et autonome vous aide à répondre à la question de comment s'adapter constamment aux changements. Nous avons également examiné de manière très générale les outils disponibles pour vous aider à réaliser ces analyses. Plus tard dans le cours, nous examinerons plus en détail ce que font certains de ces outils et comment ils peuvent vous être utiles.
1.6 Techniques et outils d'analyse des données
Dans cette section, nous allons examiner les différents types d'analyses que vous pouvez mener une fois que vous avez identifié le problème ou l'opportunité commerciale, élaboré une hypothèse et collecté les données pertinentes. Alors que la capacité de traitement continue de croître, cela a ouvert la porte à un large éventail d'algorithmes et de techniques de modélisation avancés que les organisations peuvent utiliser pour extraire des informations précieuses à partir des données.
Nous avons à disposition une grande variété de problèmes commerciaux impliquant l'analyse prédictive, la gestion des données, l'échantillonnage statistique et la conception des enquêtes. Certains sont assez simples, et beaucoup d'entre eux sont complexes, couvrant un large éventail de problématiques commerciales dans des secteurs tels que les soins de santé, les services financiers, le commerce de détail et la consommation.

Nous allons commencer par parler de l'analyse de grappes. L'analyse de grappes consiste à regrouper un ensemble d'objets de telle manière que les objets du même groupe ou cluster soient plus similaires entre eux qu'avec ceux des autres clusters. L'analyse de grappes est souvent utilisée dans les études de marché, en particulier lorsqu'on travaille avec des données provenant de groupes de discussion ou d'enquêtes. Une analyse en grappes peut être utilisée pour segmenter une population de consommateurs en différents groupes de marché afin de mieux comprendre les relations entre ces différents groupes. Cette analyse peut aider à répondre à des questions telles que : "Qui sont mes clients cibles ?", "Comment se différencient-ils sur les plans comportemental, psychographique et démographique ?" ou encore "Y a-t-il des groupes ayant des attributs similaires qui permettraient de personnaliser les produits, services, offres de prix en fonction des segments ?"
Passons maintenant à l'analyse d'arbre de décision. Il s'agit d'un outil d'aide à la décision qui utilise un graphique arborescent des décisions et de leurs conséquences possibles, incluant les résultats d'événements fortuits, le coût des ressources et l'utilité. L'analyse de l'arbre de décision est souvent utilisée pour aider les professionnels de la santé à envisager la variété des traitements ainsi que les coûts et les probabilités de réussite de chacun. Par exemple, les prestataires de soins de santé peuvent utiliser cette analyse pour évaluer les options et fournir des traitements plus rentables qui minimisent le risque de réadmission à l'hôpital. Pour analyser un grand nombre de variables dépendantes et indépendantes, nous pourrions utiliser l'analyse factorielle. Ce type d'analyse peut aider à détecter les aspects des variables indépendantes qui sont liés aux variables dépendantes. Lorsque nous recevons des données ensembles assez larges, ce qui signifie qu'ils comportent plus de variables que d'observations ou d'enregistrements, nous avons besoin d'un moyen d'identifier l'ensemble de variables ou d'indicateurs de base qui permettront d'obtenir des informations significatives.
L'analyse factorielle peut aider à identifier ce sous-ensemble réduit de variables, ce qui signifie que certaines de ces variables représentent des relations similaires à celles qui ne sont pas incluses, mais peut-être de manière plus forte.
Le Machine learning est un type d'intelligence artificielle qui permet aux ordinateurs d'apprendre sans être explicitement programmés pour le faire. Pour les détaillants avant-gardistes, les possibilités offertes par le Machine learning avancé sont illimitées. Prenons par exemple une entreprise qui essaie de prédire ce que ses clients vont acheter au printemps prochain. Les algorithmes de Machine learning peuvent déterminer la disponibilité des matériaux auprès de fournisseurs externes, intégrer divers scénarios de chaîne d'approvisionnement, et recommander la quantité, le prix, le placement en rayon et le canal de marketing qui atteindraient le mieux le consommateur cible dans une zone géographique particulière.
L'analyse de régression est un processus statistique permettant d'estimer les relations entre une variable dépendante et une ou plusieurs variables indépendantes. Ce type d'analyse vous aide à comprendre comment la valeur d'une variable dépendante change lorsque l'une des variables indépendantes est modifiée. Par exemple, une grande compagnie d'assurance souhaite identifier les caractéristiques, notamment la tranche d'âge, le revenu, le sexe, le niveau d'éducation, etc., des clients qui ont tendance à faire le plus de réclamations automobiles. Ce type d'analyse peut être utilisé pour évaluer le risque, mais aussi aider à déterminer les tarifs de divers produits d'assurance automobile.
L'analyse multivariée consiste en l'observation et l'analyse simultanées de plusieurs résultats statistiques. Cela implique souvent en premier lieu une analyse de corrélation, qui peut aider à comprendre et à visualiser les relations entre des paires de variables. La régression multivariée est une technique qui estime un seul modèle de régression avec plusieurs résultats. Lorsqu'il y a plusieurs variables prédictives dans un modèle de régression multivariée, le modèle est une régression multiple multivariée. Pour comprendre les résultats d'efficacité d'un traitement médical particulier, il peut également être nécessaire de prendre en compte des variables de confusion comme l'âge, le poids, le sexe ou d'autres médicaments que le patient pourrait prendre. Il peut y avoir plusieurs façons d'évaluer les résultats et donc, plus d'une variable dépendante et de plusieurs variables indépendantes.
L'analyse de segmentation divise une large catégorie en sous-ensembles qui possèdent ou sont perçus comme ayant des caractéristiques, des besoins, des intérêts ou des priorités communs. Souvent, l'analyse de segmentation est utilisée pour mieux comprendre les besoins des clients en divisant un grand nombre de personnes en petits groupes basés sur un schéma logique. La segmentation fournit un mécanisme pratique pour développer des produits, construire des programmes et exécuter des tactiques marketing.

L'analyse des séries temporelles (Time series) peut être utilisée pour concevoir une méthodologie permettant d'identifier les facteurs affectant la demande des passagers des compagnies aériennes sur les routes, en exploitant les données macroéconomiques, démographiques et autres données externes, au niveau local, étatique et national. De tels modèles peuvent être développés pour produire une prévision au niveau de chaque route de la demande totale de voyages en avion. Cela aide à l'optimisation de la planification des itinéraires et des capacités et à l'identification de nouveaux itinéraires pour pénétrer le marché. L'analyse des séries temporelles comprend des méthodes d'analyse des données collectées au fil du temps pour en extraire des statistiques significatives. Le cours des actions, les volumes de ventes, les taux d'intérêt et les mesures de qualité sont tous des exemples typiques. En raison de la nature séquentielle de ces données, des techniques statistiques spécifiques tenant compte de leur caractère dynamique sont requises.
1.7 Explorer les outils d'analyse de données
La demande de data scientists dans chaque industrie augmente considérablement. Pour le développement de chaque entreprise, il est nécessaire d'évaluer les données collectées. Les data scientists ont besoin à la fois des bons outils et des compétences appropriées pour produire de meilleurs résultats à partir de ces informations.
Selon le rapport de Forbes, la science des données est le meilleur emploi aux États-Unis durant les trois dernières années consécutives. De plus, selon une étude d'IBM, la demande pour les data scientists augmentera de 28% d'ici 2020, avec près de trois millions de postes à pourvoir pour les professionnels de la science des données.
La science des données est un concept qui rassemble les statistiques, l'analyse des données et leurs stratégies associées pour comprendre et analyser des phénomènes réels grâce aux données. Elle fait appel à des théories et techniques tirées de divers domaines tels que la statistique, les mathématiques, l'informatique et l'information scientifique.
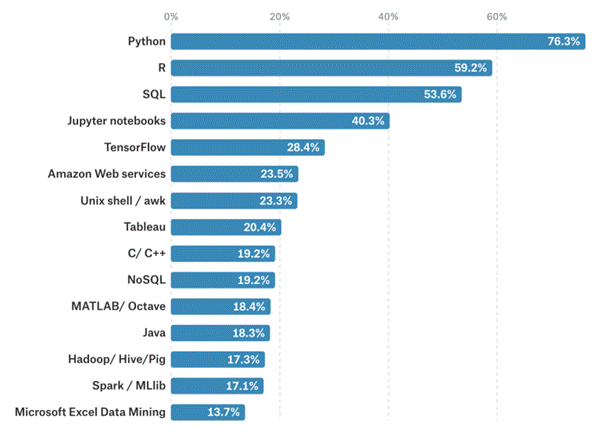
Avec l'avancement de l'apprentissage automatique, la science des données gagne en popularité. Pour comprendre et devenir data scientist, vous devez maîtriser au moins un langage de programmation (bien qu'en connaître plusieurs peut être bénéfique pour les candidats). Vous avez plusieurs options parmi lesquelles choisir.
La science des données est un domaine passionnant qui combine compétences quantitatives et statistiques avancées avec des capacités de programmation dans le monde réel.
Examinons maintenant quelques-uns des principaux langages de programmation qu'un data scientist devrait maîtriser en 2020.
1.7.1 SQL
 L'acronyme SQL signifie Structured Query Language . Il s'agit du langage standard utilisé par de nombreux
L'acronyme SQL signifie Structured Query Language . Il s'agit du langage standard utilisé par de nombreux
systèmes de gestion de bases de données relationnelles pour manipuler et interroger les données. SQL permet d'effectuer des opérations telles que la récupération, l'insertion, la mise à jour et la modification des données. Il offre une approche basée sur des instructions descriptives, ce qui le rend relativement facile à comprendre et à apprendre par rapport à d'autres langages informatiques. Cependant, il est important de noter que SQL est un langage non procédural, ce qui signifie qu'il est principalement utilisé pour interagir avec les données plutôt que pour écrire des applications complètes.
SQL est principalement utilisé pour trois choses. Tout d'abord, il est utilisé pour récupérer et lire des données à partir d'une base de données. Cela permet d'extraire les données stockées dans une table ou une base de données afin de les analyser ou de les consulter. Deuxièmement, SQL permet d'écrire des données dans une base de données. Cela signifie qu'il est possible d'insérer de nouvelles données ou de mettre à jour des données existantes dans une table. Enfin, SQL est utilisé pour effectuer des opérations de mise à jour et de modification des données. En résumé, SQL est un langage puissant et polyvalent utilisé pour lire, écrire et mettre à jour des données.
Dans le domaine de la science des données, SQL est essentiel car il permet d'accéder et de récupérer les données nécessaires pour effectuer des analyses et construire des modèles prédictifs. Les scientifiques des données peuvent également utiliser SQL pour créer des tables ou des environnements de test spécifiques à leurs besoins. SQL est souvent utilisé pour combiner plusieurs tables ensemble afin d'effectuer des requêtes complexes pour l'analyse des données.
Il convient de noter que la syntaxe SQL peut varier légèrement en fonction du système de gestion de base de données relationnelle utilisé, tels que SQL Server, PostgreSQL, MySQL, etc. Il est important de se familiariser avec la syntaxe spécifique du système de gestion de base de données que l'on utilise, tout en gardant à l'esprit que SQL reste un langage intermédiaire entre l'utilisateur et la base de données.
1.7.2 Python
 Dans cette section, nous allons examiner le rôle de Python dans la science des données et
Dans cette section, nous allons examiner le rôle de Python dans la science des données et
l'analyse. Python est un langage de programmation open source à usage général qui peut être utilisé pour une variété de tâches, allant de la création d'applications web et d'applications d'entreprise à l'analyse de grandes quantités de données. Python est populaire en raison de sa disponibilité gratuite, de son accent sur la lisibilité du code et de sa facilité d'apprentissage, ce qui en fait un choix attrayant pour les débutants. De plus, Python est apprécié pour sa convivialité et sa capacité à s'intégrer à divers outils, bibliothèques et frameworks. Il est devenu l'un des langages les plus populaires dans le domaine de la gestion et de l'analyse des données.
Python est utilisé par de nombreuses startups et entreprises technologiques pour intégrer des fonctionnalités d'analyse dans leurs produits. Les scientifiques des données utilisent Python pour gérer et analyser de grandes quantités de données rapidement. Python dispose d'un ensemble d'outils appelé "Python Data Analytics Stack" qui couvre tous les aspects du flux de travail d'analyse. Ces outils sont regroupés dans des bibliothèques Python qui sont faciles à utiliser.
Certaines des bibliothèques couramment utilisées pour la science des données comprennent :
![]() Pandas : pour l'importation et l'analyse des données, y compris le nettoyage et les statistiques récapitulatives.
Pandas : pour l'importation et l'analyse des données, y compris le nettoyage et les statistiques récapitulatives.
NumPy et SciPy : pour effectuer des opérations matricielles, mathématiques et scientifiques rapides.
Statsmodels : pour l'ajustement de modèles statistiques aux données.
Scikit-Learn : pour l'application de techniques d'apprentissage automatique telles que le clustering, la réduction de la dimensionnalité, les forêts aléatoires et la régression logistique.
![]() Matplotlib, Seaborn et Bokeh : pour la visualisation des données.
Matplotlib, Seaborn et Bokeh : pour la visualisation des données.
Apache Spark : pour le traitement des données à grande échelle sur un cluster d'ordinateurs.
En plus des bibliothèques spécifiques à la science des données, Python dispose également de bibliothèques pour gérer des données non structurées telles que le texte et les images. Par exemple, NLTK, Spacy et Gensim sont utilisés pour le traitement du langage naturel et la manipulation de données textuelles, tandis qu'OpenCV est utilisé pour l'analyse et la manipulation d'images. Python peut également interagir avec des outils spécialisés tels que Caffe pour l'apprentissage profond sur des données telles que des images, du son et du texte. En outre, Python est utilisé pour la création de sites Web et de services Web grâce à des frameworks tels que Flask et Django, qui permettent d'intégrer des modèles d'apprentissage automatique accessibles via Internet.
Python est particulièrement adapté à la science des données car il offre des fonctionnalités avancées et étendues. Il est capable de traiter des données structurées et non structurées, et il peut être intégré à des outils de Big Data tels que Hadoop ou Apache Spark. Python est choisi pour sa capacité à traiter des volumes élevés de données et pour sa flexibilité en termes de déploiement et d'intégration avec d'autres outils existants. Il permet aux scientifiques des données d'effectuer des tâches telles que l'analyse de sentiments, la prédiction des défaillances, l'analyse de texte et bien d'autres.
En résumé, Python est un choix populaire pour la science des données en raison de sa polyvalence, de sa facilité d'utilisation et de sa large gamme d'outils et de bibliothèques disponibles. Qu'il s'agisse d'effectuer des analyses simples ou complexes, Python offre les fonctionnalités nécessaires pour manipuler et analyser efficacement les données. Si vous n'avez pas encore exploré Python pour l'analyse de données, il vaut certainement la peine d'être exploré.
1.7.3 R, Qu'est-ce que le CRAN?
 R est à la fois un langage de programmation et un environnement, principalement axé sur l'analyse statistique
R est à la fois un langage de programmation et un environnement, principalement axé sur l'analyse statistique
et la visualisation graphique. Il est largement utilisé dans le domaine de l'analyse de données et est l'un des principaux outils que vous utiliserez dans ce cours et les suivants.
Il y a plusieurs raisons pour lesquelles vous devriez utiliser R :
1. Sa popularité : R est devenu rapidement le langage standard pour l'analyse statistique. Sa popularité croissante a conduit au développement rapide de nouvelles fonctionnalités, ce qui renforce sa puissance et son support. En raison de sa large adoption, de nombreux emplois et opportunités de carrière exigent des compétences en R. De plus, il bénéficie d'une large communauté d'utilisateurs, ce qui facilite l'apprentissage et le partage des connaissances.
2. Sa communauté : La communauté R est extrêmement active et engagée. Des milliers de packages ont été développés par des utilisateurs de R pour étendre ses fonctionnalités et résoudre des problèmes spécifiques. Ces packages offrent une grande variété de fonctions et de méthodes pour l'analyse de données, la modélisation statistique, la visualisation et bien plus encore. La communauté R est également connue pour son soutien et ses ressources en ligne, y compris des forums de discussion, des listes de diffusion et des tutoriels.
En utilisant R, vous bénéficiez d'une vaste gamme de fonctionnalités prêtes à l'emploi, ainsi que de la possibilité de personnaliser et d'étendre ses capacités en utilisant les packages existants ou en développant les vôtres. De plus, la nature open source de R permet une collaboration et un partage faciles avec d'autres chercheurs et praticiens de l'analyse de données.
1.8 Explorer les outils de visualisation
1.8.1 Le pouvoir de la visualisation
Dans cette section, nous allons aborder l'importance de la visualisation des données. L'objectif de la collecte et de l'analyse des données est de donner vie aux défis auxquels sont confrontés les clients, afin que nous puissions les surmonter en transformant les données, qu'elles soient structurées ou non, en informations exploitables. Les données et les analyses ne servent à rien si elles ne peuvent pas être utilisées par les utilisateurs finaux ou les décideurs. Pensez au cadre de collecte de données et d'analyse dont nous avons parlé précédemment dans le cours. Une fois que vous avez collecté les données et effectué vos analyses, vous devez être en mesure de présenter ces données de manière compréhensible pour vos utilisateurs finaux. En d'autres termes, vous devez visualiser les données.
La visualisation des données consiste à illustrer les données à l'aide de graphiques et à communiquer les informations de manière claire et efficace aux utilisateurs. Cette pratique n'est pas nouvelle. Pendant des siècles, les gens ont utilisé des représentations visuelles telles que des graphiques et des cartes pour comprendre plus facilement et rapidement les informations. À mesure que de plus en plus de données sont collectées et analysées, les décideurs à tous les niveaux de l'organisation reconnaissent l'importance des logiciels de visualisation des données, qui leur permettent de voir les résultats analytiques de manière visuelle. Ces outils aident à trouver la pertinence parmi des millions de variables, à communiquer des concepts et des hypothèses à d'autres personnes, voire à prédire l'avenir.
La visualisation est importante car le cerveau traite les informations visuelles plus rapidement que les informations textuelles ou numériques. Les utilisateurs peuvent repérer des modèles ou des tendances qui ne sont pas évidents dans un format de données plat. Les informations peuvent être interprétées par n'importe quel public, même ceux qui ne sont pas familiers avec les concepts statistiques ou techniques.
La visualisation des données permet également de prendre des décisions plus rapidement et de manière plus économique. En d'autres termes, la visualisation des données est une technique qui aide tout le monde à voir et à comprendre les analyses en cours. Par exemple, supposons que vous souhaitiez étudier les comportements des clients en fonction de leur emplacement géographique. Au lieu de parcourir des tableaux et des listes de segments de clients pour identifier différents comportements par codes postaux, vous pouvez représenter graphiquement ces données sur une carte et localiser les magasins ou les zones où des comportements spécifiques des clients se produisent. Cette visualisation vous permet de développer des stratégies ciblées pour attirer des clients spécifiques vers des emplacements spécifiques.
Dans les prochaines sections, vous verrez quelques exemples concrets de la façon dont nous utilisons les outils de visualisation des données pour résoudre de vrais problèmes commerciaux.
1.8.2 Tableau (et Tableau Public)
![]() Tableau offre différentes options, notamment une application de bureau, un serveur et des
Tableau offre différentes options, notamment une application de bureau, un serveur et des
versions en ligne hébergées, ainsi qu'une option publique gratuite. Il propose également de nombreuses options d'importation de données, allant des fichiers CSV aux données provenant de Google Ads, Google Analytics et Salesforce.
En ce qui concerne les sorties, Tableau propose plusieurs formats de graphiques ainsi que des capacités de cartographie. Cela permet aux concepteurs de créer des cartes codées par couleur qui présentent des données géographiques de manière plus accessible et intuitive que les tableaux ou les graphiques traditionnels.
La version publique de Tableau, appelée Tableau Public, est gratuite et accessible à tous ceux qui souhaitent créer des visualisations de données puissantes pouvant être utilisées dans divers contextes. Que ce soit pour des journalistes, des passionnés de politique ou des personnes souhaitant quantifier les données de leur propre vie, il existe de nombreuses utilisations potentielles pour Tableau Public. La plateforme dispose d'une vaste galerie d'infographies et de visualisations créées avec la version publique, qui peuvent servir d'inspiration à ceux qui souhaitent créer leurs propres visualisations.
Voici quelques exemples de visualisations :
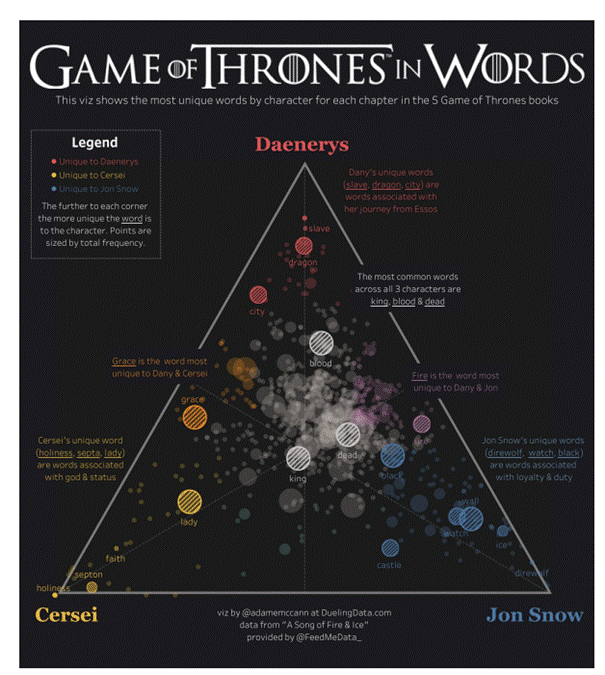
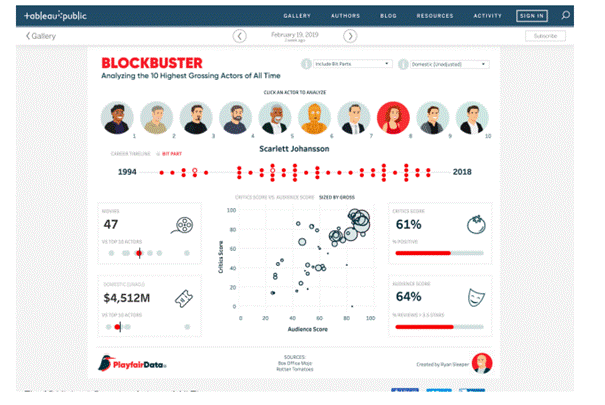
1.8.3 Datawrapper
![]() Datawrapper a été spécialement conçu pour ajouter des graphiques et des cartes aux articles
Datawrapper a été spécialement conçu pour ajouter des graphiques et des cartes aux articles
d'actualité. Les graphiques et les cartes créés sont interactifs et sont conçus pour être intégrés sur des sites Web d'actualités. Cependant, il convient de noter que leurs sources de données sont limitées, et la méthode principale pour importer des données dans l'outil est de les copier et les coller.
Une fois les données importées, la création de graphiques est simple et se fait en un seul clic. Les types de visualisation disponibles comprennent les graphiques à colonnes, à lignes et à barres, les graphiques électoraux en forme de beignets, les graphiques circulaires, les diagrammes de dispersion, les cartes choroplèthes et symboliques, ainsi que les cartes de localisation, parmi d'autres. Les visualisations finales sont similaires à celles que l'on peut voir sur des sites tels que le New York Times ou le Boston Globe. En fait, leurs cartes sont utilisées par des publications telles que Mother Jones, Fortune et The Times.
Voici quelques exemples :
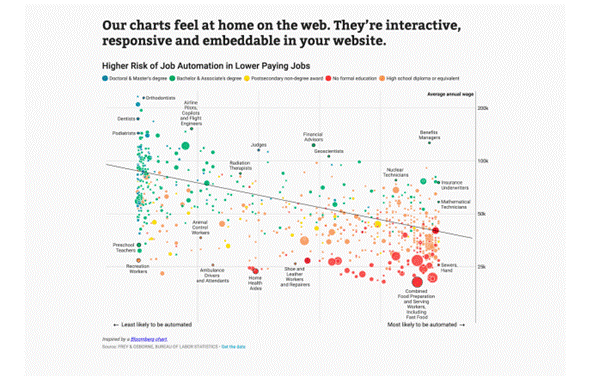
1.8.4 D3.js
 D3.js est une bibliothèque JavaScript utilisée pour manipuler des documents en utilisant des données. Pour
D3.js est une bibliothèque JavaScript utilisée pour manipuler des documents en utilisant des données. Pour
utiliser D3.js, une certaine connaissance de JavaScript est nécessaire, bien qu'il existe également des applications qui permettent aux utilisateurs non programmeurs d'utiliser cette bibliothèque. Parmi ces applications, on trouve NVD3, qui propose des graphiques réutilisables pour D3.js, Plotly's Chart Studio, qui permet aux concepteurs de créer des graphiques WebGL et d'autres types de graphiques, ainsi que Ember Charts, qui utilise le framework Ember.js.
Voici quelques exemples de visualisations :
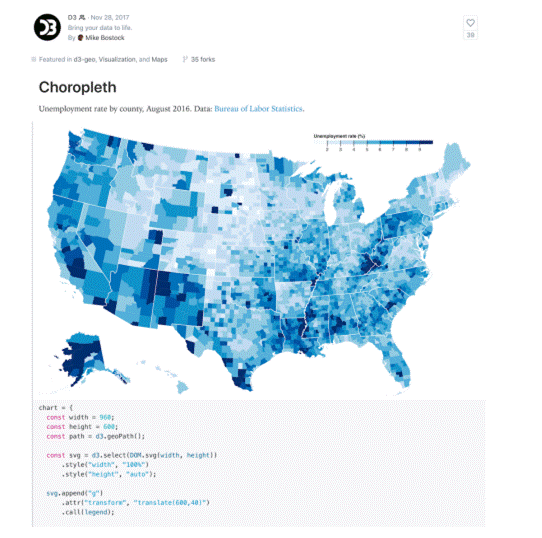
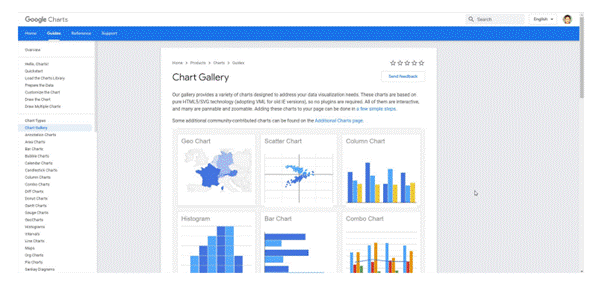
1.8.5 Google Charts
 Google Charts est un puissant outil de visualisation de données gratuit conçu spécifiquement pour créer
Google Charts est un puissant outil de visualisation de données gratuit conçu spécifiquement pour créer
des graphiques interactifs intégrables en ligne. Il fonctionne avec des données dynamiques et génère des sorties basées uniquement sur HTML5 et SVG, ce qui les rend compatibles avec les navigateurs sans nécessiter de plugins supplémentaires. Les sources de données incluent Google Spreadsheets, Google Fusion Tables, Salesforce et d'autres bases de données SQL.
Il offre une variété de types de graphiques, tels que des cartes, des diagrammes de dispersion, des graphiques à colonnes et à barres, des histogrammes, des graphiques circulaires, des graphiques en anneau, des tracés, des chronologies, des jauges, et bien d'autres. Ces graphiques peuvent être entièrement personnalisés en modifiant simplement le CSS.
Voici quelques exemples:
2 Prérequis Python
2.1 Langages
2.1.1 Langage humain
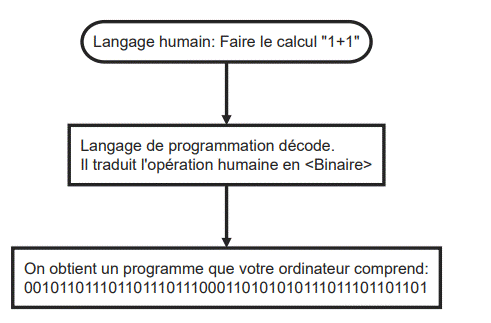
Si vous arrivez à comprendre ces suites de symboles étranges et déconcertants que sont les lettres de l'alphabet, c'est parce que nous respectons certaines conventions, dans le langage et dans l'écriture. C'est un système de communication qui permet aux humains l'échange verbal ou symbolique d'énoncés.
2.1.2 Langage machine
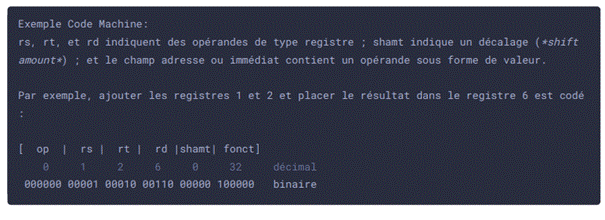
Notre ordinateur se base également sur un langage pour communiquer avec nous ou avec lui-même. Les opérations qu'un ordinateur peut effectuer à la base sont parmi les plus classiques et se composent de l'addition de deux nombres, leur soustraction, leur multiplication, leur division, entière ou non. Et pourtant, ces cinq opérations suffisent largement à faire fonctionner les logiciels de simulation les plus complexes ou les jeux super-réalistes.
Un programme n'est autre qu'une longue séquence d'instructions qui sont exécutées par le processeur. Elles sont exécutées de manière séquentielle, sauf lorsqu'une instruction de saut transfère l'exécution à une autre instruction que celle qui suit immédiatement.
Alors que le langage machine était le seul disponible à l'aube des ordinateurs, il est aujourd'hui très long et fastidieux de développer en binaire. C'est pour cette raison qu'ont été inventés des langages de programmation, afin de faciliter la communication avec l'ordinateur.
2.1.3 Langages de programmation
Les langages de programmation sont bien plus faciles à comprendre pour nous. À l'instar d'une langue naturelle, un langage de programmation est composé d'un alphabet, d'un vocabulaire, de règles de grammaire et de sens.
Les langages de programmation permettent de décrire, d'une part, les structures de données qui seront manipulées par l'appareil informatique, et d'autre part, la manière dont ces manipulations sont effectuées, selon quels algorithmes. Ils servent de moyens de communication par lesquels le programmeur communique non seulement avec l'ordinateur, mais aussi avec d'autres programmeurs. En effet, les programmes sont généralement écrits, lus, compris et modifiés par une équipe de programmeurs.
2.2 Bref histoire du Python
Python a été conçu à la fin des années 1980 par Guido van Rossum au Centrum Wiskunde & Informatica (CWI) aux Pays-Bas comme un successeur du langage ABC (lui-même inspiré par SETL), capable de gérer les exceptions et de s'interfacer avec le Système d'exploitation Amoeba.
Sa mise en œuvre a commencé en décembre 1989. Van Rossum a assumé l'entière responsabilité du projet, en tant que développeur principal, jusqu'au 12 juillet 2018, date à laquelle il a annoncé ses "vacances permanentes" de ses responsabilités en tant que dictateur bienveillant de Python pour la vie, un titre que la communauté Python lui a conféré pour refléter son long- engagement à long terme en tant que principal décideur du projet.
En janvier 2019, les développeurs principaux actifs de Python ont élu Brett Cannon, Nick Coghlan, Barry Varsovie, Carol Willing et Van Rossum à un "comité directeur" de cinq membres pour diriger le projet.
Python 2.0 a été publié le 16 octobre 2000 avec de nombreuses nouvelles fonctionnalités majeures, notamment un récupérateur de déchets à détection de cycle et la prise en charge d'Unicode.
Python 3.0 est sorti le 3 décembre 2008. Il s'agissait d'une révision majeure du langage qui n'est pas complètement rétro compatible. Beaucoup de ses principales fonctionnalités ont été rétroportées vers les séries de versions Python
2.6.x et 2.7.x. Les versions de Python 3 incluent l'utilitaire 2to3, qui automatise (au moins partiellement) la traduction du code Python 2 en Python 3
La date de fin de vie de Python 2.7 a été initialement fixée à 2015, puis reportée à 2020 par crainte qu'un grand corps
de code existant ne puisse être facilement transféré vers Python 3.
2.3 Pourquoi Python pour ce programme Data?
Python est polyvalent, flexible et possède une lisibilité facile, le rendant à la fois facile à apprendre et riche en possibilités.
De plus, il est très simple d'étendre les fonctionnalités existantes grâce à ce que l'on appelle des bibliothèques. Ces dernières assistent le développeur dans des projets spécifiques. Des bibliothèques Python, comme Pandas, aident les utilisateurs à nettoyer les données et à effectuer des manipulations avancées. Nous explorerons ces bibliothèques plus en détail dans les modules suivantes.
Concrètement, voici ce qu'on peut accomplir avec Python :
Créer de petits programmes très simples, appelés scripts, chargés d'une mission très précise sur votre ordinateur ; Développer des programmes complets, comme des jeux, des suites bureautiques, des logiciels multimédias, des clients de messagerie…
Réaliser des projets très complexes, comme des progiciels (ensemble de plusieurs logiciels pouvant fonctionner
ensemble, principalement utilisés dans le monde professionnel).
2.4 Un langage de programmation interprété
Avant de poursuivre, il nous reste quelques notions importantes à aborder.
Langage interprété: Python est un langage de programmation interprété, c'est-à-dire que les instructions que vous lui envoyez sont « transcrites » en langage machine au fur et à mesure de leur lecture. Cela signifie qu'à chaque fois que vous exécutez un programme Python, l'interpréteur Python lit chaque ligne de votre code, la convertit en langage machine et l'exécute immédiatement. C'est ce qui donne à Python sa grande flexibilité et facilite la détection et la correction des erreurs, car chaque ligne est vérifiée et exécutée séquentiellement.
Langage compilé: D'autres langages, comme le C / C++, sont appelés « langages compilés » car, avant de pouvoir les exécuter, un logiciel spécialisé transforme le code du programme en langage machine. On appelle cette étape la « compilation ». La compilation se fait avant l'exécution du programme. Le compilateur prend le programme dans sa totalité, le traduit en langage machine et génère un fichier exécutable. Ce processus permet des exécutions plus rapides et plus efficaces, car une fois le programme compilé, le code machine est prêt à être exécuté directement par l'ordinateur. Cependant, cela signifie aussi qu'à chaque modification du code, il est nécessaire de procéder à une nouvelle compilation.
Une petite mise en garde: La plupart des langages de programmation peuvent avoir à la fois des implémentations compilées et interprétées - le langage lui-même n'est pas nécessairement compilé ou interprété. Cela dépend de l'environnement d'exécution et de l'implémentation spécifique du langage. Par exemple, Java est souvent compilé en bytecode, qui est ensuite interprété ou compilé en code machine au moment de l'exécution. Python, d'autre part, bien qu'étant principalement un langage interprété, peut être exécuté en tant que programme compilé(hors programme) ou en tant que langage interprété en mode interactif. En outre, il est important de noter que la classification d'un langage comme interprété ou compilé n'indique pas nécessairement ses performances ou son
efficacité. Cela dépend de nombreux autres facteurs, dont l'implémentation du langage et l'optimisation du code.
2.5 Installer Python avec Anaconda
 est un gestionnaire de packages, un gestionnaire d'environnement ainsi qu'une distribution Python qui
est un gestionnaire de packages, un gestionnaire d'environnement ainsi qu'une distribution Python qui
contient une collection variée de nombreux packages open source. C'est un atout majeur car lorsqu'on travaille sur un projet de science des données, on se rend compte que l'utilisation de multiples packages devient rapidement nécessaire :
numpy
scikit-learn scipy
pandas
...
Ces packages sont déjà préinstallés avec Anaconda. Si des packages supplémentaires sont requis après l'installation d'Anaconda, il est possible de les installer grâce aux gestionnaires de packages, conda ou pip inclus dans Anaconda.
Cela représente un avantage considérable, car il n'est plus nécessaire de gérer soi-même les dépendances entre les différents packages. Anaconda permet même de basculer aisément entre Python 2 et Python 3 (pour en savoir plus, vous pouvez consulter la documentation officielle). De plus, il est important de noter que l'installation d'Anaconda est également la méthode recommandée pour installer Jupyter Notebooks."
2.5.1 Téléchargez et installez Anaconda
1. Accédez au site Web de Anaconda et choisissez un programme d'installation graphique - Python 3.x (A), 64 - Bit ou
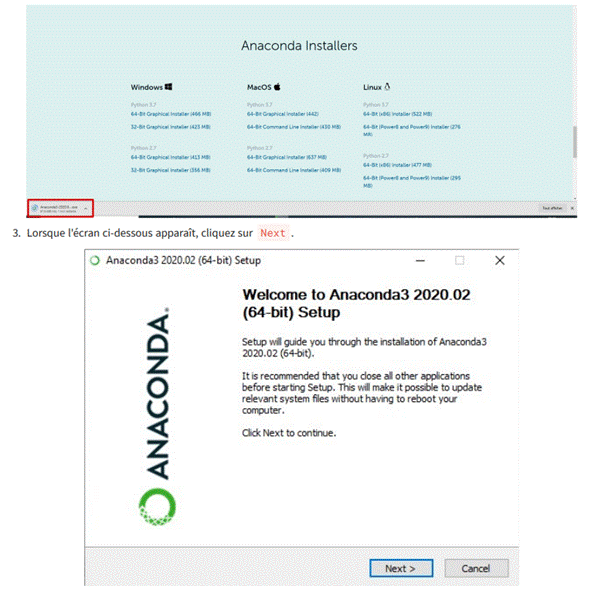

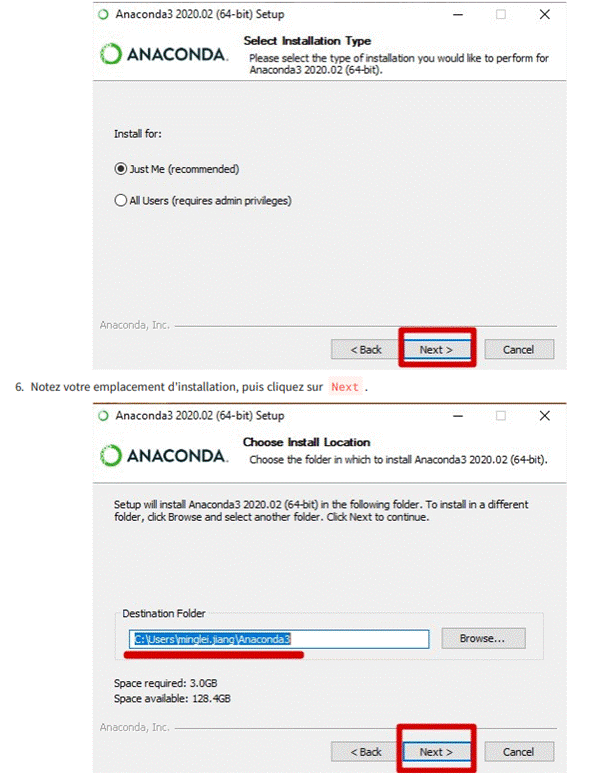
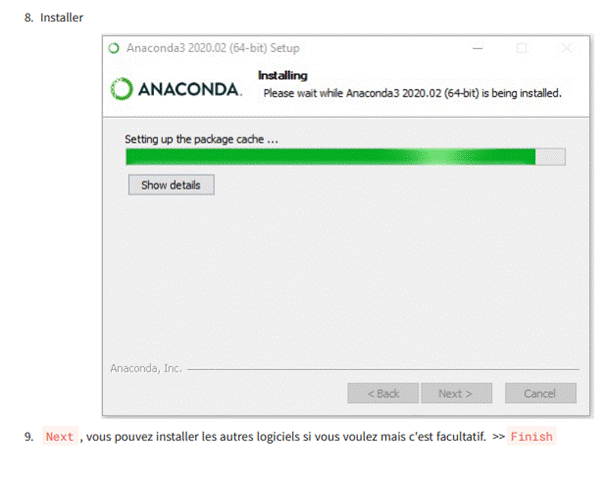
7. Il s'agit d'une partie importante du processus d'installation. L'approche recommandée consiste à ne pas cocher la case pour ajouter Anaconda à votre chemin. Cela signifie que vous devrez utiliser Anaconda Navigator ou l'invite de commande Anaconda (disponible dans le menu Démarrer sous "Anaconda") lorsque vous souhaitez utiliser Anaconda. Vous pouvez toujours ajouter Anaconda à votre PATH ultérieurement si vous ne cochez pas la case. Si vous souhaitez pouvoir utiliser Anaconda dans votre invite de commande (ou Git Bash, Cmder, PowerShell, etc.), veuillez utiliser l'approche alternative en cochant la case.
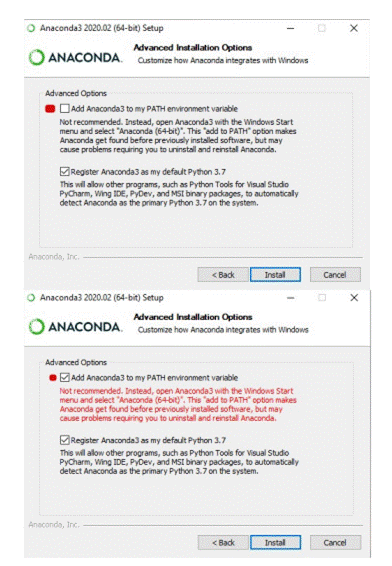

2.5.1.1 Ajouter Anaconda au chemin (facultatif)
Ceci est une étape optionnelle. C'est dans le cas où vous n'avez pas coché la case à l'étape 6 et que vous souhaitez maintenant ajouter Anaconda à votre chemin. L'avantage de ceci est que vous pourrez utiliser Anaconda dans votre invite de commande, Git Bash, cmder etc.
1. Ouvrez une invite de commande.
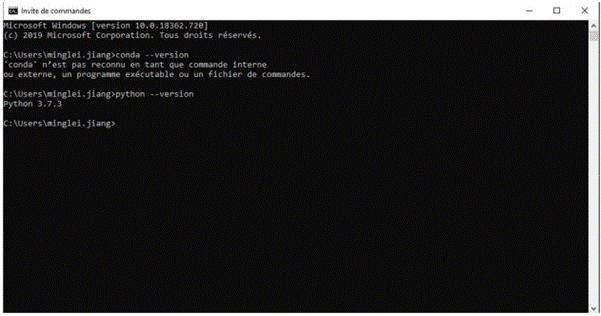
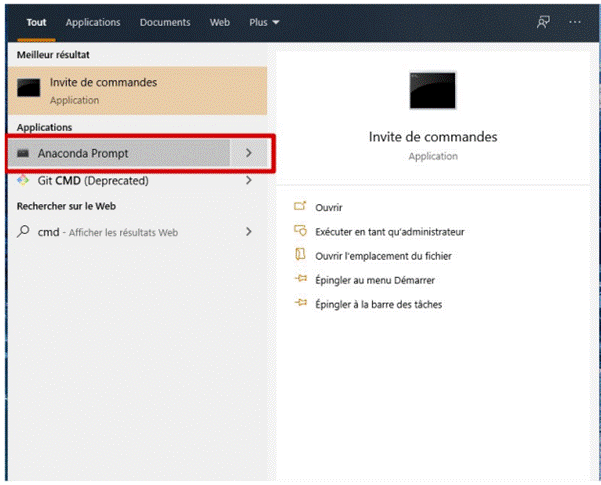
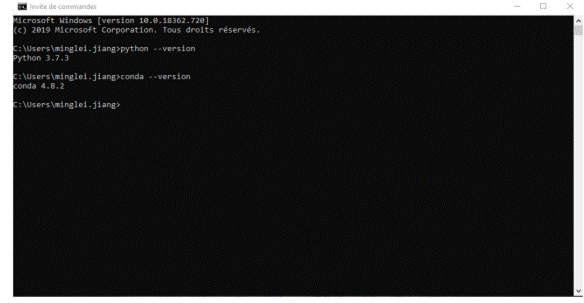
2. Vérifiez si Anaconda a déjà été ajouté à votre chemin d'accès système. Pour ce faire, saisissez les commandes suivantes dans votre invite de commandes. Ces commandes permettront de confirmer si Anaconda a déjà été ajouté à votre chemin d'accès. Si vous recevez une erreur indiquant que la commande n'est pas reconnue, comme illustré à gauche de l'image ci-dessous, veuillez passer à l'étape 3. Si, en revanche, vous obtenez un résultat similaire à celui présenté à droite de l'image ci-dessous, cela signifie que vous avez déjà intégré Anaconda à votre chemin d'accès.

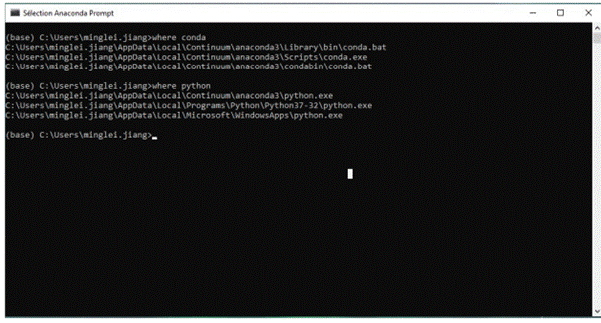
3. Si vous ne savez pas où se trouve votre conda et / ou python, ouvrez une invite Anaconda et saisissez les commandes suivantes. Cela vous indique où se trouvent conda et python sur votre ordinateur.

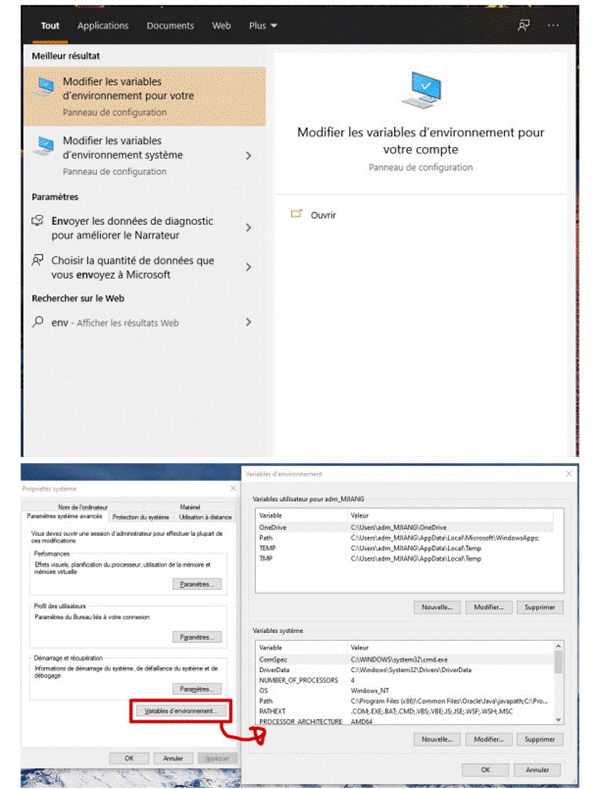
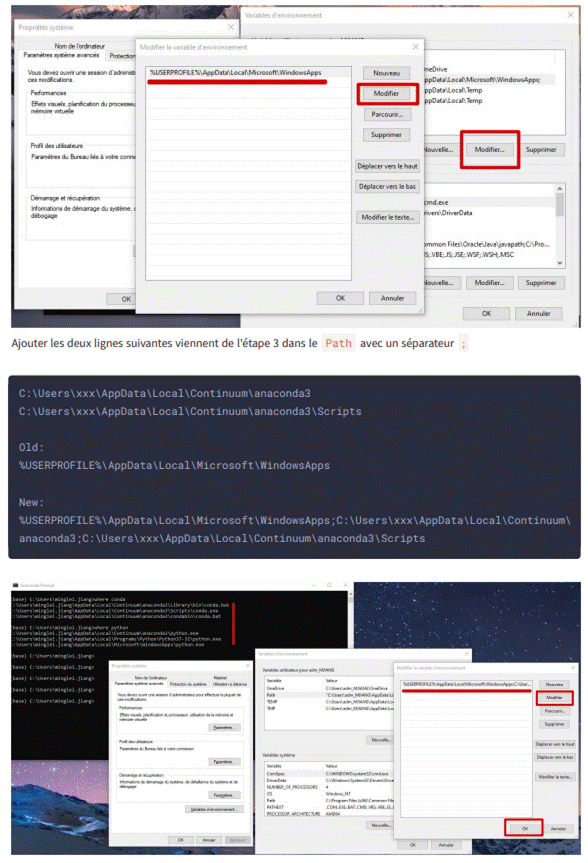
4. Ajoutez conda et python à votre CHEMIN. Pour ce faire, accédez à vos variables d'environnement et ajoutez la sortie de l'étape 3 (incluse dans le rectangle rouge) à votre chemin.
5. Ouvrez une nouvelle invitation de commande. Essayez de taper

dans l'invite de commande pour vérifier si tout s'est bien passé.
3 Prérequis Python - Jupyter Notebook
3.1 Introduction à Jupyter Notebook
 est une application Web open source qui vous permet de créer et de partager des
est une application Web open source qui vous permet de créer et de partager des
documents contenant du code en direct, des équations, des visualisations et du texte narratif. Ses utilisations incluent le nettoyage et la transformation des données, la simulation numérique, la modélisation statistique, la visualisation des données, l'apprentissage automatique et bien plus encore.
Jupyter Notebook est un environnement interactif pour écrire et exécuter du code. Le notebook est capable d'exécuter du code dans un large éventail de langages. Cependant, chaque notebook est associé à un seul noyau. Ce notebook est associé au noyau IPython, ce qui signifie qu'il exécute le code Python.
3.2 Notions de base sur Jupyter Notebook
3.2.1 Jupyter Notebook Dashboard
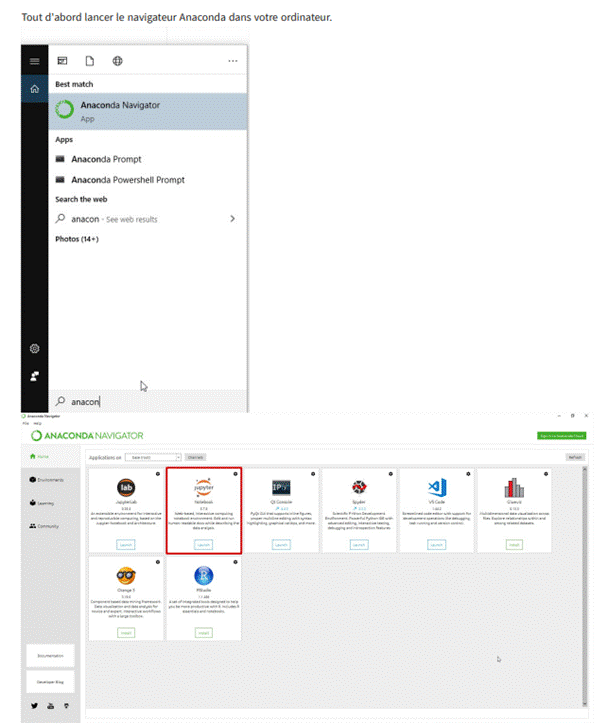
Tout d'abord lancer le navigateur Anaconda dans votre ordinateur.
Lorsque vous démarrez le serveur Jupyter Notebook pour la première fois, votre navigateur s'ouvre sur le tableau de bord du notebook. Le tableau de bord sert de page d'accueil pour les notebooks. Son objectif principal est d'afficher les notebooks et les fichiers présents dans le répertoire courant. Voici un exemple de capture d'écran de la page du tableau de bord pour le répertoire d'exemples dans le référentiel Jupyter :

Le haut de la liste des notebooks affiche une barre de navigation cliquable représentant le répertoire actuel. En cliquant sur ces liens ou sur des sous-répertoires dans la liste des notebooks, vous pouvez naviguer dans votre système de fichiers.
Pour créer un nouveau notebook, cliquez sur le bouton "Nouveau" en haut de la liste et sélectionnez un noyau dans la liste déroulante (comme illustré ci-dessous). Les noyaux répertoriés dépendent des installations disponibles sur le serveur. Certains des noyaux présents dans la capture d'écran ci-dessous peuvent ne pas être disponibles dans votre cas

La liste des notebooks affiche un texte vert "En cours d'exécution" ainsi qu'une icône de notebook verte à côté des notebooks qui sont en cours d'exécution (comme illustré ci-dessous). Les notebooks restent actifs jusqu'à ce que vous les fermiez explicitement. La simple fermeture de la page du notebook n'est pas suffisante pour les arrêter.
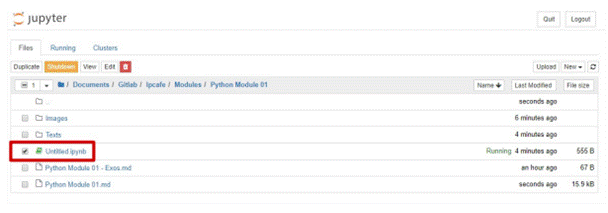
Pour arrêter, supprimer, dupliquer ou renommer un notebook, vous pouvez cocher la case à côté de celui-ci, ce qui fera apparaître un tableau de commandes en haut de la liste des notebooks (comme illustré ci-dessous). Les mêmes opérations peuvent également être effectuées sur les répertoires et les fichiers, le cas échéant.

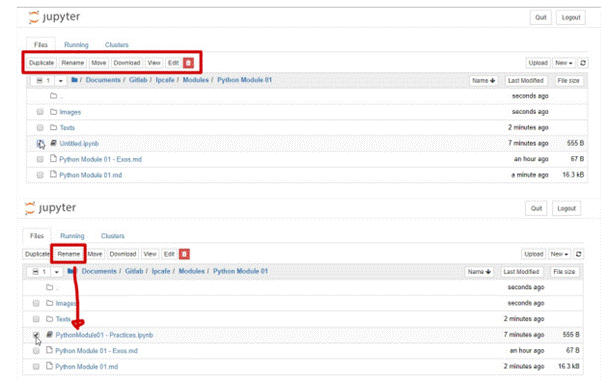
Pour visualiser tous vos notebooks en cours d'exécution avec leurs répertoires, vous pouvez cliquer sur l'onglet "En cours d'exécution". Cette vue vous permet de suivre facilement les notebooks que vous avez lancés lorsque vous naviguez dans le système de fichiers sur un serveur de notebook à long terme.

3.3 Présentation de l'interface utilisateur (UI) du notebook
Lorsque vous créez un nouveau notebook ou ouvrez un notebook existant, vous êtes redirigé vers l'interface utilisateur du notebook. Cette interface vous permet d'exécuter du code et de créer des documents de notebook de manière interactive.
Voici les éléments clés de l'interface utilisateur :
Le menu : Le menu est situé en haut de la page et contient des options pour gérer votre notebook. Vous pouvez y trouver des menus tels que "Fichier", "Modifier", "Exécution", "Cellule", "Aide", etc. Ces menus vous permettent d'effectuer diverses actions telles que créer un nouveau notebook, enregistrer votre travail, exécuter du code, insérer et manipuler des cellules, etc.
La barre d'outils : La barre d'outils se trouve juste en dessous du menu et contient des icônes représentant des actions courantes. Vous pouvez trouver des boutons pour exécuter du code, ajouter ou supprimer des cellules, enregistrer le notebook, copier, coller, etc. La barre d'outils offre un accès rapide à ces fonctionnalités pour faciliter votre travail.
Zone et cellules du notebook : La zone principale du notebook est divisée en cellules. Une cellule est un conteneur qui peut contenir du code, du texte, des images ou des visualisations. Les cellules de code sont utilisées pour écrire
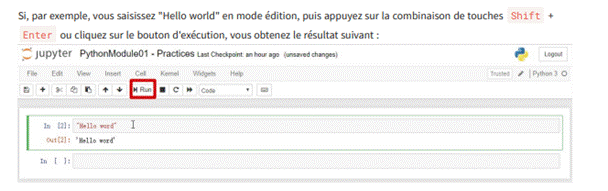
et exécuter du code, tandis que les cellules de texte (markdown) sont utilisées pour ajouter des explications, des notes, des titres, etc. Vous pouvez exécuter chaque cellule individuellement en utilisant la combinaison de touches Shift + Enter ou en cliquant sur le bouton "Exécuter" dans la barre d'outils.
3.3.1 Mode édition
Le mode d'édition est indiqué par une bordure de cellule verte et une invite s'affiche dans la zone de l'éditeur:
![]()
3.3.2 Mode commande
Le mode de commande est indiqué par une bordure de cellule grise avec une marge gauche bleue:

Lorsque vous êtes en mode commande, vous pouvez modifier le notebook dans son ensemble, mais vous ne pouvez pas saisir du contenu dans les cellules individuelles. Le mode commande est principalement destiné à l'exécution de commandes globales et à la manipulation des cellules.
Plus important encore, lorsque vous êtes en mode commande, le clavier est configuré pour utiliser un ensemble de raccourcis qui vous permettent d'effectuer des actions efficaces sur le notebook et les cellules. Par exemple, en mode commande, si vous appuyez sur la touche c cela copiera la cellule actuelle sans nécessiter de modificateur supplémentaire.
Il est important de noter qu'il ne faut pas essayer de saisir du contenu directement dans une cellule en mode commande, car cela pourrait entraîner des comportements inattendus.
Pour passer en mode commande, vous pouvez appuyer sur la touche Échap ou cliquer à l'extérieur de la zone d'édition d'une cellule à l'aide de la souris. Cela vous permettra d'accéder aux fonctionnalités et aux raccourcis spécifiques au mode commande pour interagir avec le notebook de manière efficace.
3.3.3 Navigation avec la souris
Toutes les fonctions de navigation et les actions du notebook sont disponibles à l'aide de la souris dans la barre de menus et la barre d'outils, qui sont toutes deux situées au-dessus de la zone principale du notebook.
3.3.4 Navigation avec le clavier
L'interface utilisateur modale du Jupyter Notebook a été optimisée pour une utilisation efficace du clavier. Cela est possible grâce à deux ensembles de raccourcis clavier distincts : un ensemble actif en mode édition et un autre en mode commande.
Les raccourcis clavier les plus importants sont les suivants : Entrée pour passer en mode édition et Échap pour passer en mode commande.
En mode édition, la plupart des touches du clavier sont dédiées à la saisie dans l'éditeur de cellule. Par conséquent, il y a relativement peu de raccourcis clavier en mode édition. En revanche, en mode commande, l'ensemble du clavier est disponible pour les raccourcis, ce qui offre un plus grand nombre d'options. Vous pouvez consulter la boîte de dialogue "Aide" -> "Raccourcis clavier" pour obtenir la liste des raccourcis disponibles. Amusez-vous bien !
3.4 Premiers tests
3.4.1 Texte "Hello world"
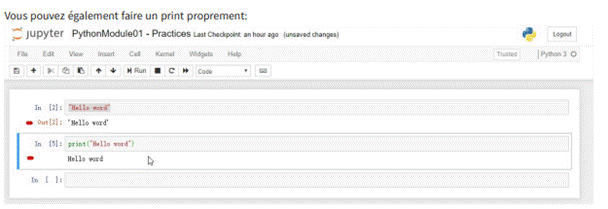
3.4.2 Calculs natifs
3.4.2.1 Saisir un nombre
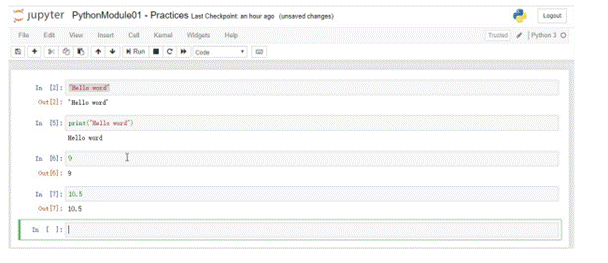
Cela ne semble pas compliqué, mais en réalité, cela signifie que nous saisissons un nombre dans le notebook et que celuici nous renvoie le résultat en fonction de sa syntaxe. Il est donc essentiel de s'assurer que notre saisie est conforme à la syntaxe attendue par le notebook pour obtenir les résultats souhaités.
3.4.3 Opérations
3.4.3.1 Addition, soustraction, multiplication, division
Nous allons vous présenter les principaux opérateurs de Python, qui seront utiles pour la grande majorité de vos programmes.
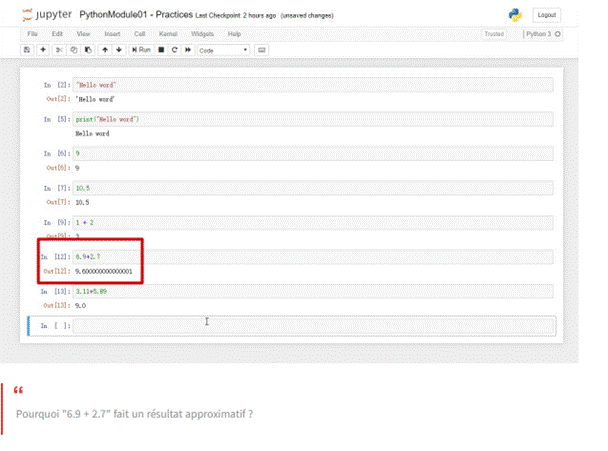
En réalité, le problème réside en grande partie dans la représentation des nombres à virgule dans la mémoire de l'ordinateur. C'est pourquoi, en programmation, il est préférable de travailler autant que possible avec des nombres entiers pour éviter les problèmes de précision. Cependant, vous remarquerez que l'erreur est minime et qu'elle n'aura pas d'impact significatif sur les calculs. Dans les applications nécessitant une précision mathématique absolue, des méthodes supplémentaires sont utilisées pour pallier ces imperfections, mais cela ne sera pas nécessaire dans notre cas.
Je vous laisse poursuivre avec le reste des opérations.
3.4.3.2 Division entière et modulo
Si vous avez effectué des divisions et observé les résultats en Python, vous avez pu constater que le résultat est généralement donné avec une virgule flottante.
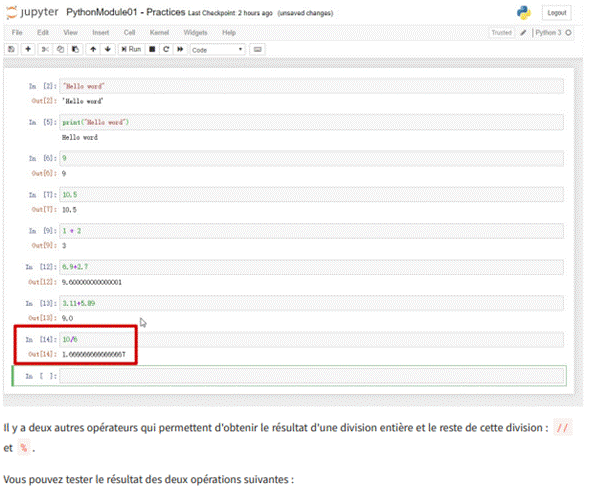
Vous pouvez tester le résultat des deux opérations suivantes :

 E-BLEARN
E-BLEARN